The growth of mobile web users is staggering. While some of us have been browsing the web on mobile devices for nearly ten years, most of the world population is only now getting there.
The web is built of links, of pages linking to other resources on the internet. But making those links manually is tedious. This is another area where modern inline editors could do better.
Couple of days ago there was an interesting post on the Dire State of WordPress, talking about the issues developers have when working with this hugely popular content management system:
It is now 2013, and the IKS project, started back in 2009 to improve content management systems through semantic technologies, has ended. Alongside Apache Stanbol and VIE.js, the Create.js inline editing toolkit was one of the major outcomes of this European Union funded effort.
Create.js and VIE were recently added to the core of Drupal 8. Just like with TYPO3 Neos, I’ll write a longer post on how things went later.

The relation between Create.js and the TYPO3 team goes back a long way. They were present in the IKS event in February 2011 in Vienna where I presented Create for the first time.

With Lukas Smith we gave the Monday keynote in this year’s International PHP Conference, titled The Internet is your application blueprint. The video is now online:
We’re now making good progress at releasing the big 1.0 of Create.js soon. The various CMS integrations - from Symfony CMF to TYPO3, and possibly Drupal and many others - have brought us a lot of new features and bug fixes, and will ensure a wide international audience for this inline editing toolkit.
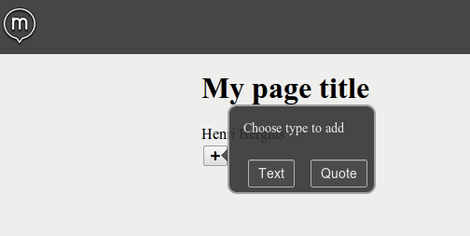
Copenhagen has been the last stop of the current Create.js tour. In here we’ve been integrating VIE and Create into TYPO3 Phoenix, the next major version of this popular CMS.
I spent the last week in DrupalCon Munich followed by FrOSCon, and gave a talk on the Decoupled Content Management story in both.

As far as open source CMSs or web frameworks go, Midgard is one of the oldest ones. We started the work on it somewhere between 1997 and 1998, and the first version was launched in May 1999. Over the years our communications and visuals have changed quite a bit, and this post aims to show some of that evolution.
For those who haven’t been following the Midgard-land, there have been some interesting developments recently. The long-term supported Ragnaroek branch of Midgard1 is slowly fading away, and much of the recent activity has focused on making Midgard2 available via the PHPCR standard, and on the new Create.js inline editing tool.

Last week we at IKS organized a two-day hackathon for developers interested in Create.js, VIE, and in new tools for editing websites semantically.

Our concept of Decoupled Content Management, together with the VIE and Create.js is really taking off. I’ve spent in various conferences this summer speaking about them.
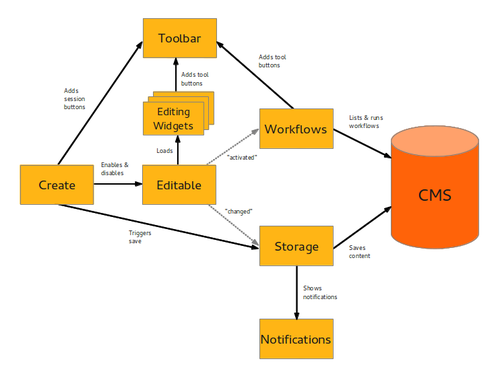
Create.js is our take on modern web editing built on semantic technologies and the ideas of Decoupled Content Management.
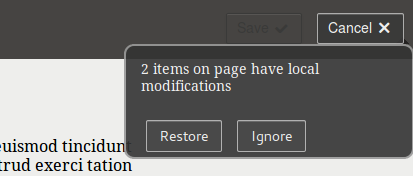
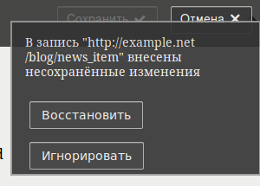
One important part of writing web content is reliability. Since everybody has had bad experiences with their current tools, the current level of trust in web editing tools is low. We’ve all been there, maybe the browser crashed, or the server-side session expired. But suddenly the article you’ve spend an hour writing is gone.

This is a liveblog from the Symfony Live 2012 event, and will be updated as the conference progresses. You can also follow the #Symfony_live Twitter hashtag
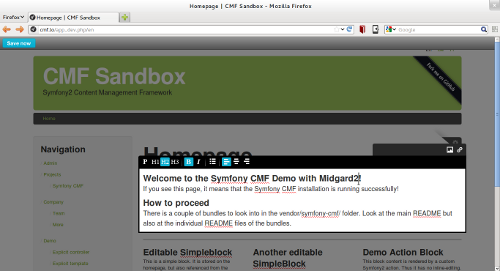
I’ve written about Decoupled Content Management before. As the Symfony Live event in Paris is nearing, I thought to give Symfony CMF a spin. Symfony CMF is a new approach at building PHP content management systems, and adheres quite well to the principles of decoupled CMS:
Update: since April 2014, Heroku’s default PHP environment has supported Composer out of the box.
It seems the idea of Decoupling Content Management is gaining momentum. On the user interface side, many projects have already adopted the VIE interaction framework and widgets from Create, and in the content repository space projects like PHPCR move forward and there are also interesting new ideas like Apache Oak. While much of this has been made possible by the...

I seem to have not blogged about this, but Open Advice, our book on Free and Open Source Software: what we wish we had known when we started, was published last month. The book was edited by Lydia Pintscher and includes essays from 42 authors, many of whom you'll recognize if you tend to go to FOSS conferences. The LWN...
It is again time to write an update on the state of IKS's two main components for the semantic editing part of Decoupled Content Management: VIE is the base semantic interaction library that handles the site's content model through RDFa annotations and Backbone.js synchronization Create is a new kind of web editing interface built on top of that. As the...
As you probably know, we at IKS have been working to decoupled content management through semantic technologies. CreateJS, together with the VIE library provide the user-facing part of this approach.
I'm happy to announce that we were able to release the first stable version of the Midgard2 PHPCR provider yesterday.Simply put, PHPCR is the future of Midgard's PHP API. Instead of having our own repository APIs, we follow the well-documented and tested PHP Content Repository specification. This allows much better compatibility with other projects, and for example the possibility to...
In PHP we’ve had a lousy culture of code-sharing. Because depending on code from others as been tricky, every major PHP application or framework has practically had to reimplement the whole world. Only some tools, like PHPUnit, have managed to break over this barrier and become de-facto standards across project boundaries. But for the rest: just write it yourself.

If you’ve been following my blog, you might have noticed that lately I’ve started doing quite a lot of Node.js development alongside PHP. Based on conversations I’ve had in various conferences, I’m by far not alone in this situation - using Node.js for real-time functionality, and PHP (or Django, or Rails) for the more traditional CRUD stuff.
VIE is a JavaScript library that makes RDFa-annotated entities on web pages editable. We started the work towards the next major version of it, codenamed Zart (for Mozart) in a Salzburg IKS hackathon couple of weeks ago.
GObject Introspection (GIR) is a way to create automatic bindings to GNOME libraries for various different programming languages. I’ve written before about the benefits of bringing GIR to PHP, and now it seems something similar is happening on Node.js.
I’m getting worried about Google. Long one of the champions of the open web alongside Mozilla, the rise of social networking silos and the app economy seem to have scared them. And like any scared organism, they lash out.

Yesterday the contracts were signed to acquire Infigo as part of Nemein. Infigo, is a consulting company focused on mobile development and web using open source tools. You'll probably at least know their CTO, Jerry of the USB finger fame. Even in the ten years of history of our company this is quite a significant move - it allows us to combine Nemein's traditional expertise on...
You may have seen my earlier post about NoFlo, the flow-based programming tool I’ve written for Node.js. It allows you to do quite cool stuff, like a visually controlled web server:
We hosted a full-day Symfony2 workshop for some of the Finnish Midgard developer community today. As I've written before, Midgard is now transitioning to Symfony2 as our PHP web framework of choice, and this workshop was organized to support that. Symfony2 for Midgard Developers View more presentations from Henri Bergius Subjects discussed included: Symfony2 as a central PHP ecosystem Basic...

As usual, Desktop Summit 2011 has been a lot of fun. I’ve been to most of the GUADEC and aKademy free desktop events in the past few years, but this was the first time I didn’t give a talk. Even that way, it was definitely worth spending a week in Berlin.
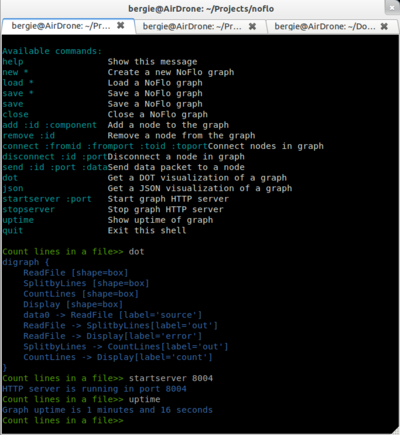
Like many, I'm currently in Berlin for Desktop Summit, the combined conference of the GNOME and KDE communities. It is a lot of fun to see all the familiar faces, and talk about the different projects going on! Now, one of the things I've talked about with people is NoFlo, my new tool that brings Flow-Based Programming to Node.js. What...
So, Symfony2 was released today. Now, you may remember me complaining about the fragmentation in the PHP community, as well as suggesting various technologies that have the power to bring the community together. But what I haven’t talked about is convergence in the area of PHP frameworks.
GObject Introspection is one of the hidden jewels of the GNOME stack: you write a library in C or Vala, and it becomes automatically available to a wide variety of languages and runtimes, including Python, JavaScript, Java and Qt.

As I’ve written before, I’m concerned about the state of the PHP ecosystem. There are lots of good applications written in the language, but there is very little code sharing between different projects, mainly because of framework incompatibilities, but also because of quite a strong NIH culture.

The Aloha Editor Developer Conference is happening this week in Hacker Dojo, Mountain View. While some other events may steal a bit of focus from this one, there seems to be a good amount of energy here. The event opened with Haymo Meran's keynote on the state and roadmap of Aloha Editor. As part of this there was an interesting...
So, Google acquired PostRank, the service calculating impact of blog posts and other items in social media. If you want something similar but without the Google tie-in, then a good option is my social impact calculator which is fully free software written in PHP. It was originally written in 2007, but the newer version has been cleaned of Midgard dependencies...
This weekend, after Falsy Values, I will be flying to San Francisco for a couple of weeks. There are some conferences: MeeGo Conference, May 23-25 Aloha Editor dev con, June 6-8 However, as there is quite some time between these two events, it would be interesting to meet cool people and/or projects. So if you're in the area, drop me...
My previous post about using Silex and AppServer-in-PHP similarly to ExpressJS generate quite a bit of interest. In the Hacker News thread there was a question about memory usage, and so I put the AppServer under siege. Memory usage stayed constant at: 13958 bergie 20 0 125m 10m 2136 S 1 0.6 0:00.28 php 13959 bergie 20 0 125m 10m...
We had the PHP Content Repository workshop at Liip in Zurich earlier this week. During the time we also discussed some other code reuse, like utilizing parts of the Symfony2 framework in Midgard. The Liip guys mentioned Silex, a cool micro-framework written on top of Symfony2. It greatly resembles the ExpressJS framework that we already use in some of our...
The IKS Project and Liip are organizing a PHP Content Repository Workshop in Zurich, Switzerland on May 8-9 2011. If you're working on PHP-based content management technologies, this event should be a very useful one to join or at least follow. What is a content repository? Content Repository is a programming interface for connecting with various persistent data stores. On...
A while back I wrote about decoupling content management. The post generated lots of good reactions, and since then our VIE library has been adopted by multiple CMSs to achieve decoupling on the UI level. Now it is time to focus on the other side of decoupling - the relation between a web framework and a content repository. I've written...
While PHP remains my primary programming language for various reasons, my recent projects have involved quite a bit of JavaScript development. And I have to say I like it: the event-driven paradigm is quite elegant, closures are a joy to work with, and tools like Node.js and jQuery really open up the possibilities of the language. But there is one...
Today on HN there was a thread on how to get the Facebook share counts for a URL. Turns out that with Facebook, just like with most social web services this is quite easy. And actually I've been doing this since 2007 to calculate news item relevance on Maemo News. Of course the social web landscape has changed quite a...
There is currently quite stern discussion going on between GNOME, Canonical and KDE about collaboration on the free desktop. Angry words have been written, and I believe much of the tension arises from the situation with MeeGo. Suddenly many developers and projects feel much more marginalized than what the future looked like, pre-112. Hopefully cooler heads will prevail before the...
My posts on Decoupling Content Management, and especially the introduction to the "build a CMS, no forms allowed" approach we took with Midgard Create have generated a lot of interest. When I first presented the approach in the recent Aloha Editor Developer Conference, many CMSs wanted to do something similar. And so we decided to strip the Midgard-specific parts out...
Event-driven programming is a paradigm that is especially familiar for GUI and JavaScript programmers. For example, it is the style used in Node.js. In the traditional PHP space it hasn't been utilized that much, but here is an example how to do it with GObject signals as provided by Midgard2. Connection events First of all we prepare a Midgard connection:...
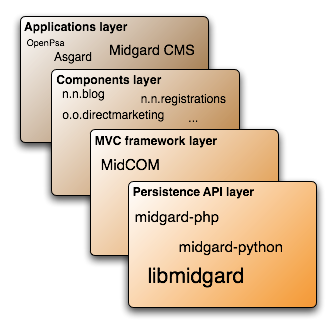
You may have noticed that quite a lot is happening in the Midgard land. Nowadays Midgard2 itself is a generic content repository that can be used for both desktop and web applications. Midgard MVC is a generic web framework for PHP5 that can be used with Midgard2 or without it. And then there is Midgard Create, the new content management...

Today it is ten years since my company, Nemein, started operating. Our team had been doing the internal Midgard-based information systems at Stonesoft, but as parts of that company were being sold, our team would've been split up. So instead we started our own business with Henri Hovi and Johannes Hentunen, with the idea that our Midgard expertise would be...
In the next-generation Midgard Content Repository we decided to focus on GObject Introspection for providing bindings to various programming languages like Python and JavaScript. The advantages for automatically generated bindings are quite obvious when compared to the situation with older Midgard versions where we had to maintain them manually. Unfortunately PHP didn't have GObject Introspection support, but that is about...

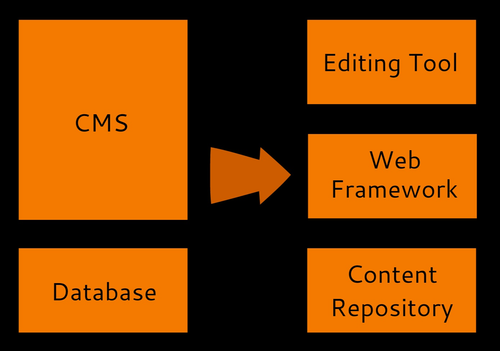
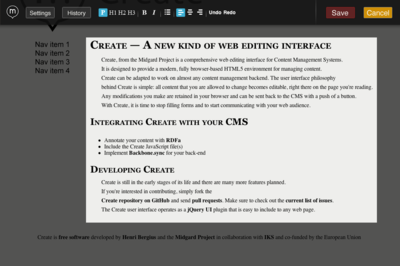
Traditional content management systems are monolithic beasts. Just to make your website editable you need to accept the web framework imposed by the system, the templating engine used by the system, and the editing tools used by the system. Want to have a better user interface? Be prepared to rewrite your whole website, and to the pain of having to...
noweb.php is a PHP implementation of the tool needed for literate programming. Wikipedia says the following about literate programming:
Python specification for a Web Server Gateway Interface has been accepted, with quite ambitious goals: If middleware can be both simple and robust, and WSGI is widely available in servers and frameworks, it allows for the possibility of an entirely new kind of Python web application framework: one consisting of loosely-coupled WSGI middleware components. Indeed, existing framework authors may even...
IKS, the EU-funded effort to add semantic capabilities to open source CMSs, will organize a semantic editing hackathon in Vienna this winter: We invite you to join us at next month's IKS Semantic Interaction Hackathon in Vienna taking place over 3-days February 24th-26th, 2011. The goal of the hackathon is to provide a framework, that enables CMS developers to exploit...

Wow, 2010 was quite a hectic year in the Midgard world. Here is a quick summary: We held three Midgard Gatherings: one in Lodz, Poland in April, one in Tampere, Finland in July and one in Gothenburg, Sweden in November. In April we announced the new directions of the project. The project completed a migration to Git (and GitHub) for...
From yesterday's PHP Advent article: PHP has been around nearly as long as there has been a Web to develop for, but it evolves constantly and is a modern programming language by almost any definition. Sure, it might not suit hipsters who only enjoy bands when they can say “you probably have not heard of them; they only formed tomorrow,”...

Midgard 10.12 was released last week as a developer preview of what is coming in the world of content repositories: MidgardCR 10.12 "Hrungnir" is a technology preview of the third generation of the Midgard Content Repository. It is released to allow developers to gain familiarity with the upcoming Midgard storage APIs and RDF storage. MidgardCR is available as a GObject-oriented...
As part of the IKS project we're working on semantic web editing. One area there is using RDFa to actually make pages editable. RDFa is a way to embed semantic information to regular HTML pages, and is already supported by some search engines, making this also a way of doing SEO. But in addition to telling search engines what the...

Snapshot from Bertrand's presentation in the Amsterdam IKS workshop: what does being an Apache project bring to the table? The answer is sustainability. IKS is an EU-funded project which will eventually end. Proper project governance handled together with the Apache Software Foundation can help the software to survive and thrive for long after that. Sustainability is something that is critical...

One of my main concerns with PHP has been the lack of ecosystem. Almost all libraries and tools are written with a specific framework in mind, creating separate ecosystems around Drupal, Zend Framework, Midgard and others instead of an ecosystem benefiting all users of the language. There have been efforts at this, like PEAR before, but they have mostly stagnated....

This should be great news for developers who want to work with a content repository: Midgard2 just landed to Debian unstable. Note that it is not the classic Midgard CMS what we're talking about here, but instead the content repository / ORM library that the CMS is built on. Midgard2 is a content repository library written on top of the GNOME...
OpenPSA is an web-based management suite for consulting companies. The GPLd suite includes functionalities like calendaring and contact management, product configurations, sales processes, project management and invoicing. The application was originally developed by Nemein but since 2008 has seen excellent maintenance work by the Content Control team. As a result of last weekend's Midgard developer meeting in FSCONS, the OpenPSA suite has...
So far on the agenda:
The (¬M)VC post gives some ideas how to improve the Midgard MVC - Content Repository interface.
There was a pretty interesting snippet in Engadget's coverage of yesterday's Nokia World keynote: "By 2013 800 million people will be using GPS-enabled devices. Soon, everything on the Internet will have a location coordinate. This is a space we intend to own." Indeed, this is a quite possible future, and one for which we with Midgard are quite well prepared...
Jos Poortvliet did an interview with me for dot KDE in this summer's aKademy and it has been online for a while now. In it we discuss things like Midgard as a storage engine for desktop applications, and Maemo's open QA process for Downloads applications. Some excepts: At maemo.org we have an appstore for FOSS applications on the Maemo platform....

To bring CMS editing to the next level, the IKS project is working on a semantic HTML5 editor. This week we had a hackathon in Helsinki focusing on implementing our ideas with the Aloha Editor. In addition to enjoying the hot summer weather here, we accomplished quite a bit and in the end were able to present the whole pipeline...
Want to work on the next generation of web editors?
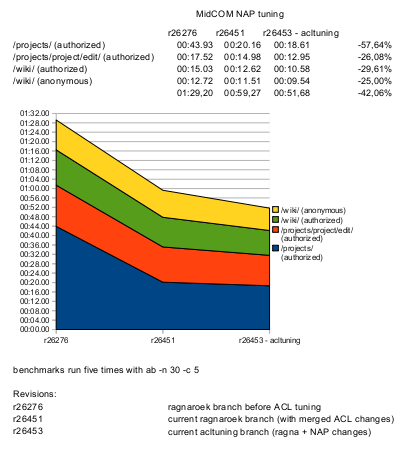
Midgard 8.09 is an industrial CMS that is now in Long-Term Supported stage, with the community maintaining it until 2013. As we all know, performance is a feature, and with a CMS framework that has lived through many changes including transitions from PHP4 to 5.2 and from Classic Midgard era to the modern APIs, there is a lot to do....

We tried to get the combined GUADEC and aKademy conferences to Tampere in 2009, but a warmer place unfortunately won. However, we will be hosting this year's aKademy so at least KDE and Qt fans will get to enjoy this beautiful northern industrial city. The main conference will be held at the Tampere University over the weekend, and then the...
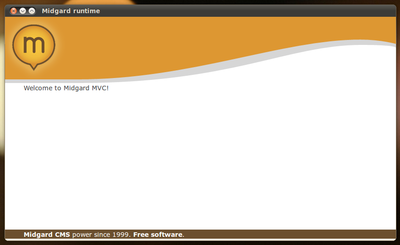
Midgard2 10.05.1 was released yesterday, bringing a long-waited feature finally to the Midgard installation packages: the Midgard Runtime. Midgard Runtime is an application that consists of a simple Qt WebKit viewer that, when run, starts a local Midgard web server on the background and connects to it. This means that you'll have the full Midgard MVC stack available on your...
A bit of folklore...
The Midgard releases have usually been named after some current event in the community. If no fitting events have been around, then names have been taken from Viking mythology.
Last year we became a partner in the European Commission -funded Interactive Knowledge Systems project aiming to increase semantic capabilities in Open Source CMSs and vendors.
Now that Midgard2 is at Long-Term Supported stage it was time to finally make the jump and migrate our development efforts to happen on top of Git, the fast version control system. To maximize project visibility and enable easy tool access we chose GitHub as the Git hosting provider. While migrating to Git we also decided to implement the Distributed Version...

Last week was the Ubuntu Developer Summit targeted at planning how the next iteration of the operating system, Maverick Meerkat, targeted at a October 10th 2010 release, would look like. The event was held in a spa resort off in the countryside near Brussels. A place where the developers were comfortably separated from the busy towns by forests and country...

Midgard2 10.05 "Ratatoskr" was released yesterday, moving the Midgard Content Repository into long-term supported state as outlined in my recent post. Ratatoskr should provide a stable storage system for both desktop and mobile application developers. Web developers will also benefit from Midgard MVC, the PHP framework that already runs services like Qaiku.com. The release includes: Content Repository API bindings for the...
Two weeks ago we had the Midgard Gathering in Poland, and some big decisions were made there. I've been meaning to blog about them, but the volcano eruption in Iceland kept me busy by providing an interesting trip through New York and Moscow. Midgard2 The next Midgard2 release, 10.05 "Ratatoskr" will be a long-term support release, intended to provide a...
The NoSQL movement seems to be pretty active, advocating a move away from traditional relational databases: ...developers have become crippled by being able to only think of data in terms of Rows and Columns. There's a multitude of database paradigms: Graphs, Trees, Objects, and so on. Furthermore, databases limit developers to SQL, which is great for certain kinds of set...
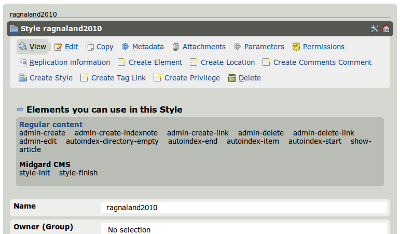
For a while now there has been discussion about making template editing easier with Midgard CMS. In the Ragnaroek series we have a very comprehensive template system where all output from the system can be overridden. While the possibilities have not always been easy to discover, things should be better in the next Ragnaroek LTS release. To access the template...
I'm doing a talk today in the Bossa Conference about using Midgard as a content repository for mobile applications. As part of my presentation I wrote some simple example code for using the Midgard APIs in Python, and thought they would be good to share to those not attending the event as well. The idea of a content repository is...
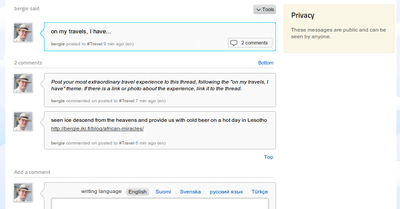
Qaiku, the conversational microblogging service that launched a year ago had a refresh that launched today. While it hasn't yet convinced the twittering masses, it has already proven itself as a lot more thoughtful platform for the Finnish online community, and as a valuable workstreaming tool. The new version looks quite nice and fresh. Notice the privacy information on the...
Which CMS does The Real Story Group Use? (Tony Byrne / CMS Watch): The answer is, we use an open-source platform called "Midgard." We picked it nearly ten years ago, and it has held up fairly well.... One of the things we like about Midgard actually makes it rather unsuitable for many simpler publishing scenarios: it is highly object-oriented. This...
MeeGo is the new mobile Linux platform developed by Nokia and Intel. As the community is forming up, we thought that it would be good to enable people to use their maemo.org identities also on the MeeGo web services (as well as on any other OpenID enabled website). For this, let me introduce Maemo's OpenID provider. First of all, go...

Bossa Conference, an event about mobile development with free software technologies will be held on March 7th-10th in Manaus, Brazil. This year I'm speaking about using Midgard as a replicated storage layer in mobile applications, with examples for multiple programming languages and toolkits. The idea behind the Midgard content repository is that instead of coming up with your own file formats you can...
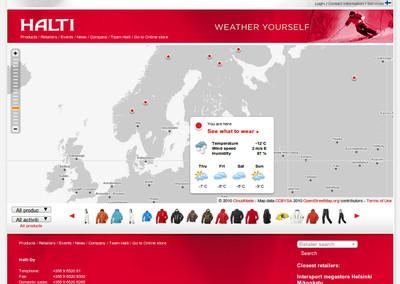
Last week the Finnish outdoor brand Halti launched a pretty interesting web service. While many outdoor brands focus on extreme sports that don't really have much to do with the reality of most of their customers, Halti connects their product lineup to the needs of the site visitor by utilizing both weather and location. This means where ever they are or...
There certainly is a lot of buzz about Apple's rumored Tablet product. Daring Fireball writes: If you’re thinking The Tablet is just a big iPhone, or just Apple’s take on the e-reader, or just a media player, or just anything, I say you’re thinking too small — the equivalent of thinking that the iPhone was going to be just a...

2009 was a pretty active year for the Midgard content repository project, and so it is good to take a look at some of the highlights: Midgard2 finally became a reality, bringing us a fully legacy-free modern Midgard implementation. There were two releases: 9.03 Vinland and 9.09 Mjolnir. Midgard2 works just fine also in desktop applications and mobile devices like...
Location is an important context that web services can utilize for fun or smarter user interaction. In past getting location used to be difficult, but now thanks to good IP locationing databases and browser geolocation capabilities it is becoming a lot easier. But to be really easy, the framework you're using should provide user's location built-in, without you as an...
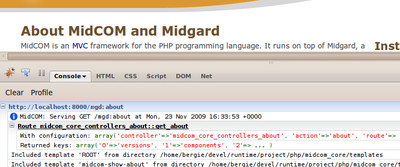
Firebug is a Firefox extension all web developers are familiar with. Now when developing with the MidCOM3 MVC framework it is possible to get your debug information straight from Midgard to Firebug: This is built on top of the excellent FirePHP extension, which helps you get data not only from regular web pages but also from AJAX requests. Currently we...
Joint post of Henri Bergius and Michael Marth cross-posted here and here. Web Content Repositories are more than just plain old relational databases. In fact, the requirements that arise when managing web content have led to a class of content repository implementations that are comparable on a conceptual level. During the IKS community workshop in Rome we got together to...

Mjolnir, the new major release of Midgard2 Content Repository is now out. Named after the hammer of Thor, this release finally provides a real content repository that can be used by both desktop and web application developers. In addition to being a GObject-powered content repository for PHP, Python and Objective-C, the Mjolnir release provides several significant goodies on top of...
An increasing number of web services and applications are emphasising search terms or pre-selected websites instead of allowing users to enter any address they choose. This is worrying, as while searches are more user-friendly, URLs are the heart of an open web where anybody can publish without obscure business dealings or oppressive app store policies. There are many examples of...
Midgard is a very active free software project, and it is quite difficult to keep up with all the changes, decisions and discussions happening around it. Therefore I decided to bring the Midgard Weekly Summaries back. Midgard Weekly Summary #75: October 2nd 2009 MWS has been running before, with 66 issues released between 1999 and 2002, and 8 issues in...

After a brief summer motorcycling break the fall is shaping up to be quite full with conferences. Here is the current list: September 30th - October 1st: OpenMind and MindTrek in Tampere, Finland I'll give a talk about the Midgard project and how our company has evolved together with it. In addition Linux-tekijä awards, where I was in the awards...
Gadgetopia makes an argument for building your own CMS: "See — the problem with a full scale Content Management System is that it has too many opinions. Those opinions were though of by somebody other than you and the needs of your organization. The more developed a content management system (or any piece of software, really) the more “opinions” it...
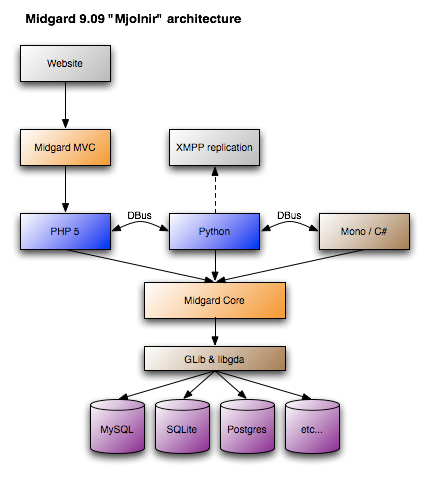
I had to make some updates to the architecture diagrams, and I thought to publish them here to showcase the difference. Midgard was a CMS framework for PHP: Midgard2 is a more universal content repository where CMS is just one application: Please note that more choice in databases and web servers is not the only goodie provided by Midgard2. You...

Content repositories can be useful for your application. In the PHP track of FrOSCon on Aug 22nd there will be a talk about this: Midgard2: Content repository for your PHP application Content repositories allow you to separate the actual front-end of your application from background processing tools. More than just their underlying databases, they impose common rules for data access,...
MDK laments the demise of the simple file in the onslaught of storage services: Sure, the applications still give you a way to share things and take them out of the storage. You can export a contact out of your address book as a vcard file. But the role of The File here is slowly being reduced to a role...
I gave my Midgard2: Content repository for desktop and the web talk yesterday in GCDS. The slides are available on SlideShare. The main idea was that any application that deals with structured data could benefit from using a content repository like Midgard2 or CouchDB. So, what is a content repository? It is a service that sits between an application and...
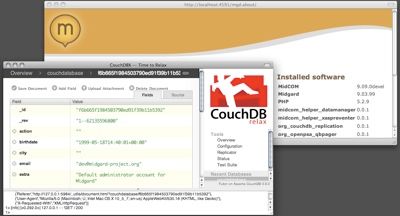
CouchDb is a really cool document-oriented map/reduce database that is nowadays an Apache project. Previously we created the distributed CRM application Ajatus on top of the system and ported CouchDb to Maemo. Here in Gran Canaria Desktop Summit CouchDb has been somewhat a hot topic, as the Ubuntu project is planning to use it as the content repository for desktop...
Dave Neary summed this up well: ...I fundamentally disagree with discouraging someone from pursuing a technology choice because of the threat of patents. In this particular case, the law is an ass. The patent system in the United States is out of control and dysfunctional, and it is bringing the rest of the world down with it. The time has...

Just a little teaser before we all head out to countryside for the midsummer weekend: Yes, you're seeing the software versions right. The screenshot is from the "About Midgard" screen of Ragnaland, a hybrid setup of Midgard's MidCOM MVC framework from Midgard1 (MidCOM 8.09) and Midgard2 running in an App Builder instance (Midgard 9.09). Still requires some tweaking and bug...
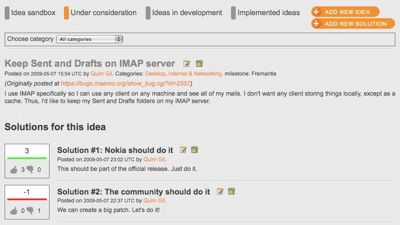
Bugzilla isn't really the best place for contributing and discussing new ideas for a software project. Like Ubuntu and openSUSE before us, the Maemo community now also has a better tool for this: Maemo Brainstorm. Maemo Brainstorm, developed as part of our efforts to the April 09 Sprint is a new web service that follows the model of Drupal's IdeaTorrent,...
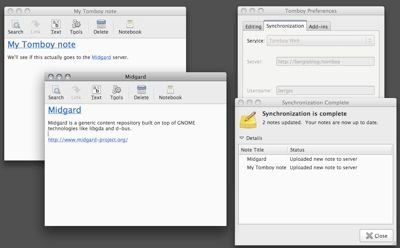
Some very interesting developments in desktop wiki land: Tomboy, the popular note-taking application for GNOME and OS X now supports web synchronization. The developers of Tomboy have launched Snowy, a web service that allows you to synchronize and access your notes online. As the API is documented, I decided to add support for it in Midgard too. This way the...
This week is the Interactive Knowledge project general assembly and requirements gathering workshop in Salzburg, Austria. My notes from the meeting days can be found on Qaiku: Day 1: general situation, tasks and requirements Day 2: tools, persistent storage, meeting the community As things are happening, it is also possible to follow progress on the #iks-project Qaiku channel or the...
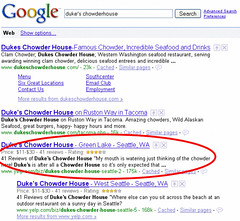
This February I wrote how search engines play an important role in emergence of Semantic Web, and now it is becoming a reality: Google introduced a feature called Rich Snippets which provides users with a convenient summary of a search result at a glance. They have been experimenting with microformats and RDFa, and are officially introducing the feature and allowing...

Ten years is a long time. Exactly ten years ago we were sitting in a cramped office room in Espoo with Jukka Zitting, frantically trying to put a release together. We had been building a web platform for our living history group, and it had become useful for others too. We both were Linux users, and back then the concept...

GUADEC will be arranged this year together with aKademy as the Gran Canaria Desktop Summit on July 3rd - 11th. The event will be an excellent opportunity to learn about some new technologies for the Linux desktop: GeoClue and libchamplain presentation (Sunday morning):GeoClue is the position information service, and libchamplain is a very nice Clutter map widget. Together they provide...

After the long wait, Midgard2 was today released to the world. This marks a big change in the scope of what Midgard is. Instead of building a CMS, we've built a generic content repository that can be utilized in web, mobile and desktop applications. As MDK wrote when announcing the Objective-C bindings for Midgard: ...it provides an objectified view to...
So, Oracle bought Sun, and MySQL with it. Since MySQL runs much of the current web, I'd imagine many developers are now concerned with the future of that database and looking at alternatives like PostgreSQL. But instead of locking yourself to another specific database, how about going with a content repository? Content repositories are services that wrap different storage back-ends...
CloudAve reviews the CrunchPad browsing device, and concludes that these days, a single computer is just not enough for all our needs: A tablet for lazy surfing, a netbook for travel, an iPhone for when we don’t even want to carry that much, a full laptop for everyday work, and even a full desktop as the multimedia workhorse: at these...
Midgard2, the content repository for multiple programming languages that we've all waited for so long is now in beta stage, and some services like Qaiku and St1 ReFuel already run on top of it. To get you started, here are some of the best Midgard2 blog posts out there: Midgard 2: More than just PHP, more than just CMS -...
Last night Finnish energy company St1 launched ReFuel, their new biofuel product. ReFuel is interesting in the sense that it is produced from biowaste, and so no farmland is used in its production. To support the product launch we helped to create ReFuel Tehdas, an application for converting internet trash (bad pictures, advertisement banners) into money. To use it, you...
May 8th 1999: The Midgard Project has finally released the first public version of Midgard Application Server Suite. The new release contains Midgard core libraries, a PHP3-based web application server for the Apache platform and the needed web-based administration tools. May 8th 2009: It's time for celebration - Midgard CMS turns ten in May! The decade of Midgard will be...

As is customary, Midgardians are again meeting in Linköping, Sweden. This time most of the focus is on Midgard 9.03 "Vinland" familiarization, and discussing what shall be done for 9.09. So far discussed: New XML-based element inclusion syntax <mgd:include /> Moving MidCOM3 administrative tools behind a mgd: URL namespace Implementing database views in MgdSchema API Initializing Midgard database in stand-alone...
Via Bertrand there is a meme of CMS vendors analyzing how they are doing with CMS Watch's CMS reality checklist. Here's how Midgard 8.09 copes: 1. Our software comes with an installer program. Yes. First you install Midgard using your distributions's native package management tools, and then let datagard do the rest. It will install all necessary PEAR packages, create...
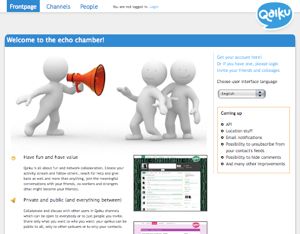
I've been beta testing the new conversation-oriented microblogging service Qaiku, and after some negotiations we today signed a cooperation agreement to join in developing the site: Qaiku is a microblogging service, focusing strongly on discussion. Microblogging differs from ordinary blogging by the length of the posts, more topical content and automatically published micromedia, such as Flickr photo stream, Audioscrobbler stream...

Qaiku is the new conversation-oriented microblog that many former Jaiku users are migrating to. While the team is still working on APIs and other features, it is already possible to pipe your qaikus to other social services like Twitter and Facebook. This blog entry will show you how. The first step is to register to ping.fm, a service that can...
Microblogging is all about conversations. About interesting ideas, and the opinions and clarifications to those. About discovering things happening around you. But to be honest, Twitter and its clones like Identi.ca do not do that so well. Ease of posting, and good external tools might be there, but what lacks is the possibility to have real conversations. That is where...

Benjamin Otte is asking on Planet GNOME why the GNOME desktop doesn't do more to integrate with the cloud. He reasons that: ...GNOME developers are not “web-enabled”. We’re a bit like Microsoft in the early 90s: We focus on the local computer and ignore the internet. which, to my experience is somewhat true. I went to GUADEC for the first...
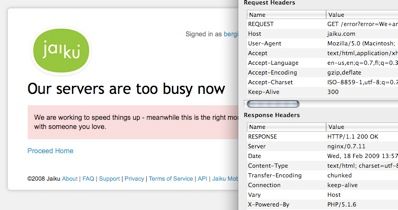
Jaiku, the microblogging service I use, has been frustratingly often down in the last couple of days, apparently kicking off another mass migration towards Twitter and Brightkite. And they report it only in human-readable way, not in fashion a browser, a proxy or a search engine would understand it. While being down, Jaiku still responds with HTTP 200 OK: HTTP...
Thanks to the IKS project, I've spent some thought lately in how to make something practical from the concept of Semantic Web. As always, the big issue is getting the semantic information out there. In a strongly typed CMS like Midgard, many semantics can be gathered from content structure directly, but to really get there we need users to add...

Good work, Debian Project: Debian GNU/Linux 5.0 is released! As Midgard release manager Piotras wrote in his Jaiku: debian Lenny (5.0) is out. It means vinland will run on stable debian. It means we have php5-xcache in stable debian, we have solr in stable debian. It means we can think about Midgard in official 'squeeze' (debian testing) Big step indeed,...
I've been following the Java Content Repository story since the OSCOM conferences of old. Last week, I took a new look at it as Bertrand Delacretaz from Day held a JCR presentation in the Interactive Knowledge Consortium meeting. And you know what? Midgard and JCR resemble each other quite a lot: Both follow a repository-centric approach, where the content repository...

I spent this week at Salzburg Research in Austria attending the kick-off meeting of the Interactive Knowledge Consortium, a €6,5m EU-funded project to introduce semantic capabilities into open source content management systems. Nemein is participating in the project as one of the six industrial partners. For the next four years we will be working together with cool CMS companies like...
FOSDEM, held in Brussels on Feb 7th and 8th, is the most important free software event of the year in Europe. While I'm going to Poland instead of there this time, the event is an excellent opportunity to learn more about two projects I'm involved with: Midgard and a replicated P2P filesystem Sun Feb 8th 2009 at 16:20, Room Ferrer...
As it was for the Zend folks, 2008 was quite a busy year also in the Midgard-land. I think the last time there was so much activity and energy in the project must've been sometime in the early days. Here are some highlights from it: Midgard 2: finally a reality The big news of 2008 was that Midgard 2, the...

Frustrated with how some Midgard-powered community sites were being spammed (their fault, not using CAPTCHA or registrations, I know), I decided to add a little feature to MidCOM's forum and page commenting tools: automated spam filtering. To make this happen, I hooked Midgard with the Mollom anti-spam service. When enabled, all posts sent to Midgard either on-site or using the...

Since Midgard does now Python nicely alongside PHP, some Midgardians have recently been looking at Django as an optional web framework to use with Midgard's replicated storage system. Looking at other systems than yours every now and then is great, as you can get some ideas. First such idea to come to Midgard from the Django world is error interceptors,...
Maemo.org, the community site for Nokia's mobile Linux environment has this week been upgraded to 8.09.2 Ragnaroek, the much faster and long-term supported version of the Midgard framework. Thanks to Niels and Piotras for working with me on this! in October, I spent quite a bit of time optimizing this release, shaving off an estimated 60-70% of queries through some...

At Nemein we do maintenance for quite a few servers of our customers. While some customers have their own Linux distribution preference - usually RHEL - in most cases we have a say what distribution runs their servers. So far this has been debian, but now we're going for Ubuntu Server. The reasons for this are quite simple: Ubuntu follows...

The second Midgard Gathering of 2008 is this weekend in Otaniemi, Espoo. Happened so far: Thursday Sebastian Bergmann gave us a training session on PHP software testing, as as result we now have over 1000 unit tests for the MgdSchema API for PHP. We also looked at Selenium for acceptance testing and deployed a continuous integration server for MidCOM 3...
From the Midgard Project: The Midgard Project switched to a new synchronized release model with the 8.09 "Ragnaroek LTS" release. Synchronized release model means that a major release of Midgard will happen every six months, tuned to be part of the larger Linux software ecosystem as described by Mark Shuttleworth: WHAT IF you knew that the next long-term supported releases...
Gadgetopia has a post on how CMS's should provide an API for content filtering. Since Midgard is persistent storage API first, and CMS only second we obviously have nice APIs for doing exactly this. In this case we're running a query and checking if a different user is allowed to see something, as specified by Gadgetopia: Hey, CMS, I have...

Since the Midgard Gathering is next week, I thought it would be time to write down some conversation starters related to it. Clear vision One important thing we need to settle on is a clear vision for Midgard. It should be a vision everybody in the community can agree with, and a vision that will benefit the user base. I...

Harmaasudet, the living history group we started in mid-90s, and the reason why I originally got into software, recently migrated back into the Midgard platform. Their webmaster and Nemein alumnus Heikki asked me for some history of Midgard, and this is what I wrote: Well, original Midgard was completely programmed in order to run the Grey Wolves site. We hacked...
LinkedIn, the popular resume maintenance tool just got a little smarter: they added an applications catalogue that can make your profile there more dynamic. This is good as then potential business partners can find out more about myself from a single source, and I need to do less work to keep it up-to-date. I immediately added three apps, displaying my...

Last weekend we went to the Free Society Conference and Nordic Summit in Gothenburg to talk a bit about the new direction Midgard has been taking: making it a general replicated persistent storage library for multiple programming languages. The CMS itself is just an application using the library. The basic idea is that the cloud is a trap that will...

I wrote earlier how a free software project never stops as long as there are people interested in it. Looking at Midgard's Ohloh analysis, I found a nice example:
Can you see a change when former MidCOM lead developer Torben withdrew from the project?
FSCONS is the main Nordic conference on free software and free culture, held on October 24th - 26th in Gothenburg, Sweden. The schedule has lots of interesting stuff, including Wikipedia, Embedded Qt, OpenStreetMap and Jabber. But in addition, there will be two sessions on Midgard: Midgard by Henri Bergius: I will be talking about this long-term open source CMS project...
Midgard CMS switched to a synchronized release model this summer, and the first fruit of it is Midgard 8.09 Ragnaroek, a Long-Term Supported release launched last week: Ragnaroek LTS is a Long Term Support version of Midgard for which bug fixes and minor feature improvements will be supplied by the Midgard community for several years. It is recommended that all...
Midgard follows Ubuntu's synchronized release schedule, and releases packages for that platform, but otherwise we have little to do with the distribution. Still, I found the following in Mark Shuttleworth's Jaunty Jackalope announcement interesting: Another goal is the the blurring of web services and desktop applications. "Is it a deer? Is it a bunny? Or is it a weblication -...

With beta2 out today, the new Midgard 8.09, or "Ragnaroek LTS" is finally coming. PHP4 has been dropped, many optimizations made, and now that Prototype has been dropped in favor of jQuery, I think we will finally be able to live with it as the Long Term Support release. But before Ragnaroek is stable a lot of testing has to...

The Free Software Foundation's GNU project turned 25 last week, and the English humorist Stephen Fry made a video to commemorate it: Benjamin Mako Hill posted some thoughts on how the first generation of free software developers has grown: Certainly, GNU has matured and accomplished wonderful things in last quarter-century. More importantly perhaps, it's produced wonderful progeny. It has spawned...

I know, according to roadmap we all should be now focusing in hammering out bugs in Midgard 8.09, or as we call it, "Ragnaroek" instead of working on MidCOM 3. But Tero had a specific problem he needed to solve, and I wanted to ensure it was done right. And so I ended up adding support for context injectors into...
Rasmus Lerdorf's excellent talk on PHP and simplicity in FrOSCon introduced me to concept of green programming. To quote the Green Programming blog: Just like we should aspire to use renewable energy sources to help the health of the planet, we should also use reusable software elements to create robust, healthy code for our customers. Eco-friendly practices might be thought...

Cross-posting this to Planet GNOME, as it is sure to be interesting to the community there, especially as Midgard is becoming much more than just CMS: There is a project in works by me to rewrite Midgard’s core engine from plain C to Vala. Midgard 8.09’s code is taking huge use of GObject infrastructure and Vala is so good in...

A thousand years ago, men from my lands traveled here in search of opportunities and adventure. Now, due to intercontinental relationships and working permits, I follow their footsteps. While Istanbul didn't score perfectly in Monocle's Quality of Life index, I still find it a quite appealing place for a web worker. The lifestyle is more relaxed than in the north,...

I'm again in the FrOSCon conference in Sankt Augustin, having found the conference last time reasonably big, but relaxed. I will be giving my GeoClue talk again on Sunday (16:30 in HS5). Here are some notes from the conference: PHP 5.3 is going to have alpha2 next week. Namespaces could be nice in MidCOM, but I wonder how well they...
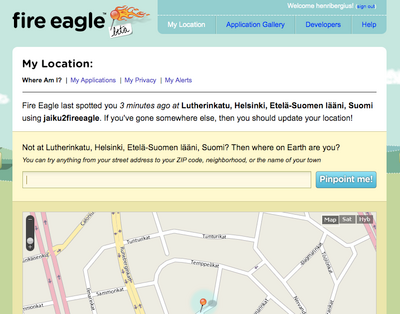
Yahoo! Fire Eagle, kind of "GeoClue for the Web" was released last week. It acts as a central hub collection position information from services like Plazes and Dopplr, and with a simple PHP script, Jaiku. Services needing user's location can then ask it from Fire Eagle instead of having to support all the services separately. Midgard's positioning framework has been...

MidCOM is a PHP MVC framework where you create a site by building a tree structure and assigning components for the various folders. Each component is its own PHP application that can handle all URL requests under that folder using a set of configured routes. In addition to making normal requests to the various routes available, routes provided by other...
The release synchronicity plan was accepted, and therefore Midgard will be switching from SVN to git, and the concept of feature branches. With feature branches the idea is that each feature or bug fix is being developed in its own branch, and only landed to trunk (master in git terminology) when ready. This keeps the trunk clean and easy to...

At the moment the prevailing wisdom is that each CMS should have its own user interface, and that user interface should be web-based. But there is also another way: separating the user interface from the CMS using a CMS-neutral protocol called Neutron. According to Sir Tim Berners-Lee, the earliest web browser was also an editor. And the late 90s Netscape...

I've posted about new directions needed for Midgard's release coordination and marketing. After some discussion, I think it is time to vote and make decisions. The proposal is to switch to synchronized releases. This would make development more predictable, marketing efforts clearer and more focused, and align us with the release synchronicity movement implemented in related projects like GNOME and...
Looks like 2008 is forming up to be a quite busy conference year, at least looking at my Dopplr page. Here are the events I'm speaking (or performing as is the case with Haedong Kumdo) in this fall: Aug 2nd: Haedong Kumdo Seminar in Mayo, Ireland: part of the Finnish team Aug 9th - 10th: aKademy in Sint-Katelijne-Waver, Belgium: Location-aware...
maemo.org has been having user profile pages for a while, and now it was time to overhaul their visual design. Here is the new design: In addition to new visuals, the profile page also now displays automatically collected data like user's latest blogs and favourited news items, and allows entering of new data like IRC nickname and multiple email addresses....
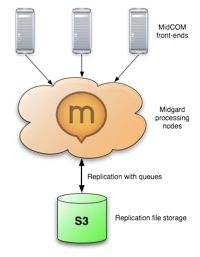
There has been quite a lot of talk about cloud computing lately. When we had the previous MidCOM3 coding sprint we discussed over beer how Midgard2 could fit into the cloud. As replication has been a core Midgard feature since the early days, that was the obvious angle to start looking from. The way I see Midgard2 in the cloud...
The Coccinella IM project published an interesting entry on potential marketing impact of synchronized software releases: How can we copy the marketing successes of Apple and Microsoft to open-source? Some may suggest we need someone like Steve Jobs, whilst others would like to spend more money on launch events. They are both wrong! Trying to copy Steve Jobs or Microsoft's...
There has been some discussion about the deployment model for the upcoming MidCOM 3 MVC framework for PHP and Midgard 2. My suggestion was to enable WebDAV on all MidCOM servers so content structures, configurations and templates could be moved between them with simple drag-and-drop. This week we're having a MidCOM 3 coding sprint, and now we can already mount...
Today has been an important day for the Midgard Project - development versions of both active Midgard branches were launched: Midgard 1.9.0alpha1 "White Nights" released Midgard 1.9 has been designed as a version easing the transition from Midgard 1.x to Midgard 2. To aid developers, the release includes both the classic Midgard APIs that are now deprecated, and the new...

Latest MidCOM 2.8 has a feature that has been resurrected from earlier in the series: document locking. The point of locking is to prevent accidental simultaneous editing of a document by multiple users. When user starts editing a document via datamanager-powered form, the document will be marked as locked for that user. Other users accessing the document will see a...
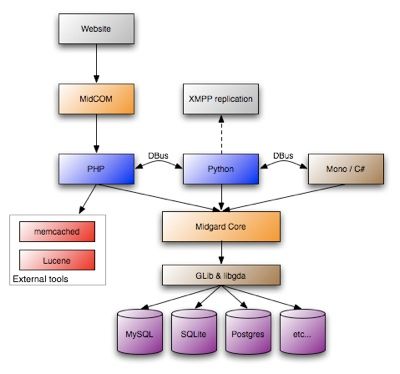
As Midgard 2 is already in alpha stage, I though it would be good to update the architecture diagram to showcase the new Midgard structure. This includes multiple language bindings, MidCOM3, D-Bus interprocess communications and other things. With these changes Midgard 2 can function either as a full-fledged CMS, a PHP MVC framework, or a persistent storage framework for multiple...
We're currently in the stage where two branches of Midgard: 1.9 and 2.0 are both in active development. Midgard 2 is the fully legacy-free next generation of Midgard, and 1.9 is a transitional release that provides both Midgard 2 and Midgard 1 APIs to ease migration. The active development status means that bugs are bound to be found in them....
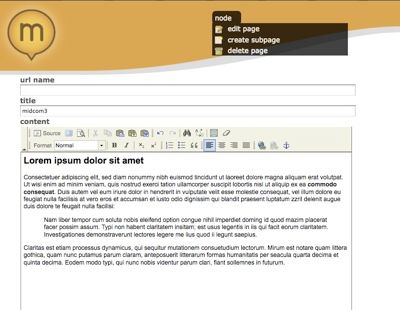
While watching Everaldo work on the upcoming Midgard C# bindings, I decided to try running Midgard 2 with lighttpd. After quite a lot of struggling to get latest SVN checkout to compile on my mac, and some playing with lighty rewrite rules, I was greeted with a working MidCOM 3 page: So, after such a long time, Midgard 2 is...
Yesterday Arttu Manninen posted notes on how to use git for MidCOM 3 development. In addition to the repo.org.cz usage he described, the other way to work on the next generation PHP framework for Midgard is using the GitHub service.
Rails on the Run has quite good tutorial.
Technorati Tags: midcom, midgard, git, github
In his recent blog post, Piotr Pokora showed how the the D-Bus API will work in Midgard 2. D-Bus is an interprocess communications system that is used heavily in modern Linux desktops like GNOME and KDE. With Midgard, the same system now becomes available for PHP and web applications:
midgard_python "service":
import dbus.mainloop.glib
import _midgard as midgard
A List Apart 256 has a very interesting article on Taking Control of Your Maps, explaining how to provide richer and more customized web map solutions using tools like OpenLayers and Mapnik, and the free data provided by OpenStreetMap: For the practical developer who wants to add geospatial information to a site or application, the Google Maps API has been...
This document has been written as a quick Midgardized version of the nice “Django at a glance” tutorial, in order to explain how the new and upcoming MidCOM 3 framework works. In addition publishing this as a blog post, this document will be maintained in the MidCOM 3 version control tree. MidCOM 3 has been designed to be an extensible...

Semantic web, the platform that could enable new businesses to rival the likes of Google has for a long time been a distant promise. Much of this has been because the standardization bodies have focused on too difficult and impractical technologies instead of building it on top of existing web implementations. Microformats are a more pragmatic approach: by using simple...

There has been some discussion on how the different items in the Midgard roadmap fit together. Here is my company's view on how we see ourselves proceeding. Baseline: Midgard 1.8, MidCOM 2.8 and PHP 5.2 At least in our company we're trying to consolidate all customers to these version numbers. MidCOM 2.8 is a very capable (if heavy) platform that...
I've been a happy user of the Jaiku S60 client for a while now. It not only allows me to coordinate things with my friends on the move, but also positions my phone using cell IDs. So far I've used the WiFi positioning based Plazes client for updating location on my site, but the thought of also using Jaiku has...
This is a historical moment:
On the side of FOSDEM we went today to the XMPP devcon held here in Brussels. In there we started formulating our ideas of XMPP publish/subscribe (XEP-0060) based replication for both Midgard and Ajatus.

Last weekend a group of European Midgard developers gathered to Linköping, Sweden for the Midgard developer meeting of winter 2008. Over the last four years Linköping seems to have established itself as the place to hold the winter meeting, with summer meetings differing in place. In 2006 we went to Poznan, Poland and in 2007 to Otaniemi, Finland. The meeting...

We're in Linköping, Sweden for the Midgard developer meeting, and I suddenly realised the Midgard community really likes Nokia's internet tablets. Not only does maemo.org run on Midgard (earlier this week "sideported" to MidCOM 2.8), but many Midgardians are also active Tableteers. So no wonder over the course of the meeting we saw the maemo application manager display an interesting...
While last autumn was more quiet, this spring seems to have a number of events that I'm going to: Feb 15th - 17th: Midgard developer meeting in Linköping, Sweden. Lots of hacking and talking about Midgard 2 and MidCOM 3 Feb 22nd - 24th: FOSDEM in Brussels, Belgium. I'm going for Open Business Organisations of Europe (OBOOE) meeting on behalf...
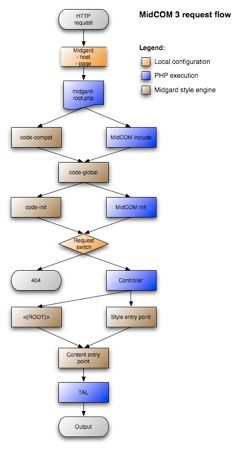
MidCOM is the PHP framework used for building sites with Midgard CMS. Over years it has accumulated lots of components and features, and currently weights around half million lines of code. At the same time the design, while being well designed, suffers from having to work around lots of limitations in PHP4 and the old Midgard API. In preparation for...
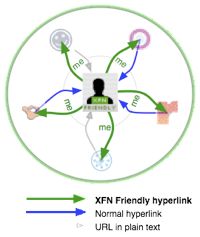
If you're using multiple social web services, you will also have multiple online identities. For creating a comprehensive online persona, consolidation between the various profiles would be useful. To aid in this, and to enable social network portability, Google has started aggregating social networking data marked up in the XFN and rel=me microformats to build a comprehensive social graph. Having...
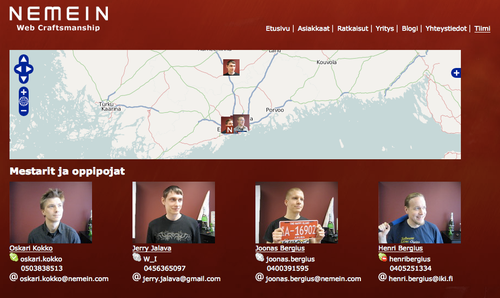
We're in the process of publishing the new corporate website today. While our web needs are actually quite simple, the site includes some nice features. As we're involved in GeoCMS development, one such feature is the active team map: The OpenStreetMap gets automatically updated as we move around. This doesn't however mean that we've GPS collared our employees, but instead...

MySQL, the world’s most popular open source database has today been bought by Sun Microsystems. Congratulations to Monty and the rest of the team! Billion dollars, quite a deal in the free software space.
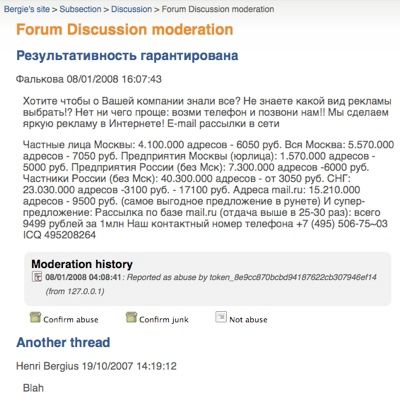
Midgard’s discussion forum component, net.nemein.discussion now has new moderation UI.
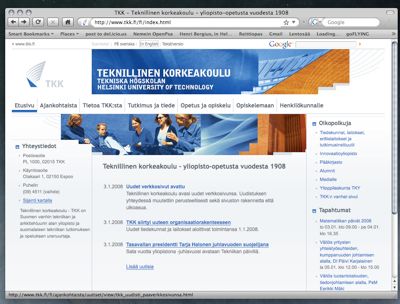
Helsinki University of Technology (TKK), the oldest university of technology in Finland launched their new site today:

Last week I was pondering how to add attention profiling support to the Midgard framework, and now it is there. Midgard is able to gather user’s interests and attention from multiple sources: del.icio.us bookmarkslast.fm listened trackssocial news favoriting...and other imported APML sources What remains to be seen is how this will be used to make websites smarter and more useful...

Information overload is becoming a major issue, and more sophisticated solutions will be needed to tackle it. With Midgard we’ve already taken some steps into this space by creating tools for calculating newsworthiness of stories in order to present only relevant ones to a user.
MidCOM, the PHP framework for Midgard CMS has over hundred components for various purposes ranging from blogging to waste management statistics. But even with all of them it is sometimes useful to embed some custom PHP scripts to a site. The old method of doing this was using a custom style for a folder and including PHP files there, which...
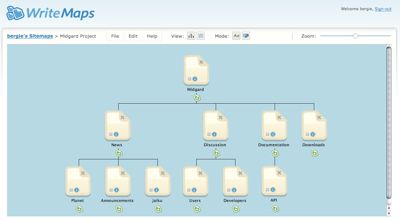
WriteMaps.com is a handy web-based tool for planning website structures in a mind map -like format. The tool allows for storage and working on the designs in collaborative fashion.

Simon Josefsson was giving a talk on OpenID in the Scandinavian Free Software Conference. OpenID is a lightweight single sign-on and auto-registration system for web applications. In concept it is quite similar to Shibboleth but easier to deploy.

VectorMagic from Stanford University Artificial Intelligence Laboratory is a pretty interesting tool. You upload a bitmap image, give a few parameters about it, and you get a vectorized version back.

Midgard is quite a huge framework, and so caching is needed to keep things efficient. To that effect, MidCOM 2.4 in 2005 added a major feature of caching generated pages until they needed reconstructing.
Karma: The total effect of a person’s actions and conduct during the successive phases of his existence, regarded as determining his next incarnation. (wiktionary)
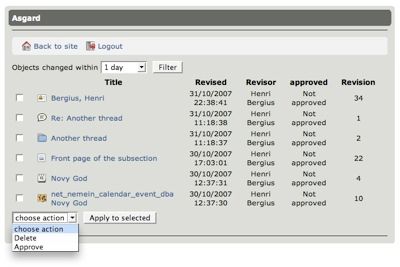
Asgard is the new administrative interface for Midgard we’ve been working on for the 1.9 release. Today its welcome page just got a lot more useful as we added a way of listing recently modified objects of any type and performing mass actions on them:
Inspired by Kore Nordmann’s post Why are you using BBcodes?, Midgard now has integrated support for the HTML Purifier library. From the HTML Purifier site:
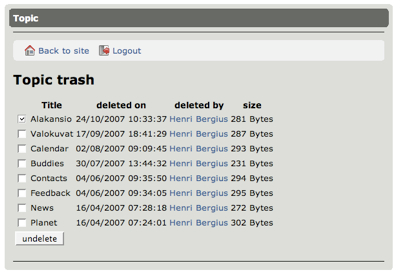
A trash can feature for Midgard was discussed originally in the 2006 Komorniki Midgard developer meeting, and the APIs for it made their way into the 1.8.0 release. Yesterday I added trash can browsing and undeletion support into Asgard, the new administrative interface.
As initially instigated by Tuomas and later prepared by Joonas, Midgard has now switched to the Tango icons and colors. This helps to modernize the look-and-feel and make it more consistent across components.
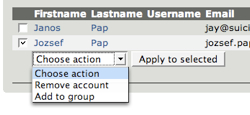
In past there have been two types of user management tools for Midgard: the built-in ones that have supplied lists of users, and then custom-made ones. With former the problem has been that when you have thousands of users the HTML views become slow to load and near impossible to use.

Quim wrote earlier on why red hearts matter in maemo news. The red hearts are important as they bring important news items forward in the maemo social news aggregator. But sometimes there are also news items that are not at all relevant to the maemo community. To solve the problem with them we’ve now added a burying option:
CouchDB is a very interesting evolution in open source data storage: an ad-hoc document database with replication support. I heard the first time about CouchDB when Jan Lehnardt was presenting it in FrOSCon a month ago, and became immediately very interested.
Column Two has an interesting post titled What does a web CMS do? with a table listing features that are integral to a web CMS, and what can be handled separately.
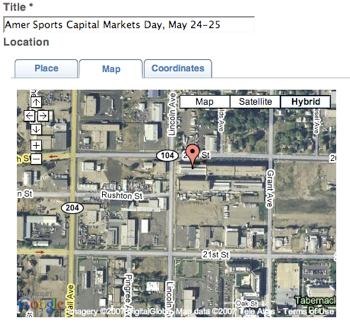
Midgard has had quite cool GeoCMS features for a while now: any objects can be positioned and retrieved via position, and maps are easy to display anywhere. We also can use cool services like Plazes for automatically positioning new content created by users.
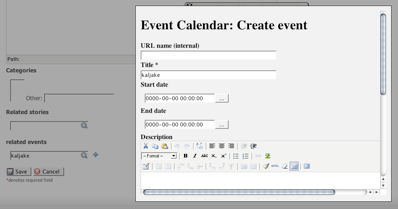
Midgard’s datamanager2 form handling library has a very nice jQuery-powered chooser widget which enables search-based selections. This is often used in situations where the data set user is choosing from is large, as is often the case when selecting persons from a large organization for instance.

Today we’ve been hacking in the woods as part of the MidCOM Performance Sprint. Together with yesterday’s bug day this has resulted in quite a few commits.
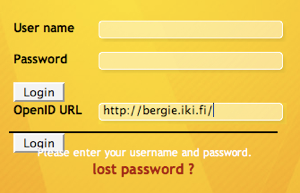
Inspired by a talk in FrOSCon on Sunday, I went and implemented OpenID support into Midgard on the flight back. OpenID is a quite cool system for cross-site single sign-on and auto-registration. With OpenID your user identity is tied to a web address you control, for example http://bergie.iki.fi/. Every time I want to log in to an OpenID-enabled website, that...
I’ve noticed this is something I end up showing to people in every conference, and therefore probably makes sense to blog it.

MidCOM is the PHP-level framework of Midgard CMS. With its nearly 500K lines of code, it every now and then is good to sit down and focus on performance optimization.
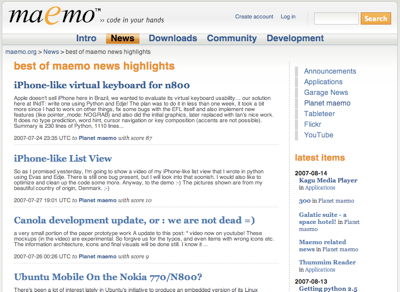
Today has been a big day for maemo.org: not only was the Maemo Community Calendar released for beta testing, but we also launched the new Social News section on the site. Social news is an area where users can easily with one glance see all interesting things happening at the moment in the maemo world.
Asgard is the new administrative interface being built for Midgard. The main objective is to get rid of the legacies of Aegir and SpiderAdmin by replacing them with a smart system that auto-generates admin UIs for all installed MgdSchema types. But small improvements also count, and so we decided to deploy CodePress for code editing:
I’ve started working on a new Social News section for maemo.org. The idea of this area is to provide a centralized view on what is happening at the moment in the maemo community.
We had some discussion about what features make CMS a GeoCMS with GeoPress and Drupal geo developers in State of the Map, and a list should be published soon. Based on our discussions I decided that Midgard should also make it easy to actually display positioned data on maps.

Midgard has been an early supporter of internationalization in open source CMSs, adding UTF-8 support already in 1999. Today I however got an innocent request: One thing to be considered is i18n and Unicode support, since the community wiki is the perfect place to host translated docs. I was quite confident that things would work out OK, but knew that...
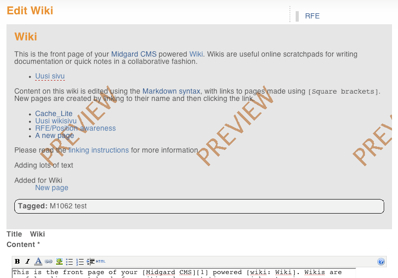
Since Maemo.org started using the Midgard wiki component there has been discussion on whether it is feature-complete or easy enough to use. Main complaints have been about the “latest changes” view not supporting sub-wikis and missing Markdown documentation.
We’ve just switched Midgard and MidCOM to use the Trac project infrastructure. Seems very nice, especially as it uses Midgard site accounts for authentication.
My blog is now running on a Kotisivut.com virtual Debian box. It should provide much faster response times and better stability for my blog than the older solution. I will be sharing the server with Arttu from kaktus.cc.
Asgard reborn. Work has started to build a new administrative interface for Midgard. Asgard is completely powered by Midgard’s new reflection APIs and automatically supports managing all MgdSchema objects installed on a server
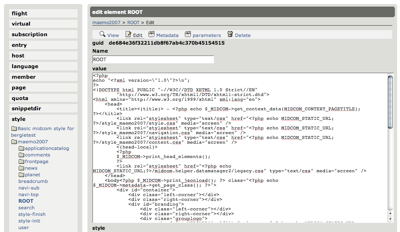
We had a 19-hour hacking session last Friday with Arttu, Rambo and Jerry to build new “general Midgard admin UI” targeted at replacing Aegir and Spider Admin with something that follows both MgdSchema and MidCOM DBA rules and APIs, and so is compatible with Midgard 2.
We helped to launch two interesting new Midgard-powered sites yesterday.
This week has been busy with Midgard-related releases. The MidCOM 2.8 and Midgard 1.8.3 combo is very enticing, as it enables trying out the new replication system.
This summer I will be at these events:
There has been discussion on some changes to the near future roadmap of Midgard and MidCOM. Here are the proposed changes in nutshell:
Today is the Accident Prevention Day in Finland.
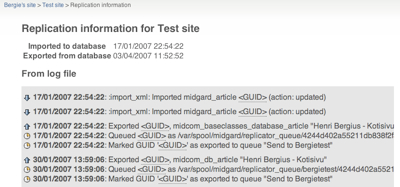
Midgard’s new replication service has been under work since January. Now the work is finally starting to bear fruit, as we’re doing the first tests with real production data.
Midgard developer meeting on June 1st - 3rd. The next Midgard developer meeting will be held in Helsinki University of Technology campus. Both developers and users are most welcome to join the event! There have been some thoughts of combining it with a Midgard seminar during friday the 1st.
The rise of web applications like Gmail and Basecamp is bringing the good old offline vs. online debate again into picture.
I just held my presentation about how the Midgard community works in the Norwegian Open Source in Business conference. Here are the slides:
Arttu Manninen upgraded his blog to MidCOM 2.6 and is now on a blogging frenzy together with his padawan Jaakko Tepponen. Lots of good snippets of information about Midgard usage are appearing…
I’m back from the arctic hunting trip. One week away from even the cell phone network felt really good and the aurora borealis were simply gorgeous. Now it is time to again catch up with happenings in the Midgard community…
Finnish parliamentary election of 2007 was last Sunday. Unfortunately my candidate, Mikko Rauhala from the Liberal party and of Electronic Frontier Finland fame didn’t make it.
This week’s MWS is a bit thin because of time constraints. This means some interesting things like MidCOM’s new style editor will be left to MWS #70.
Happenings this week
Midgard is becoming smarter about tags. Now it not only supports tagging any objects and making tags contextual, but also machine tags:
Midgard Weekly Summaries resurrected
Open Source Content Management System Summit 2007 will be held in Sunnyvale, CA on March 22nd and 23rd. I’ve proposed the following session:
MWS, for those who don’t remember it, was a Midgard Weekly Summary. It was published every week from mid-1999 to sometime in 2001, first by me and later by Ken Pooley from the Sewanee University.

When this bunny joined our company, I wrote that the plan was to make our CRM system talk to the Nabaztag. Today the first step was taken by making a Nabaztag notifier plugin for the org.openpsa.notifications library.

While my site is publishing a lot of photos, I’m using Flickr as my central photo storage location. The reason for this is simple:
Midgard has a very powerful page templating system, and this has been noted in CMS Watch kudos lists several times.
If you want to cache your MidCOM site, but are on a chrooted environment and so can’t run Squid, one option is to use the Cache_Lite PEAR package. To do this, you must have access to the page elements used on your site.
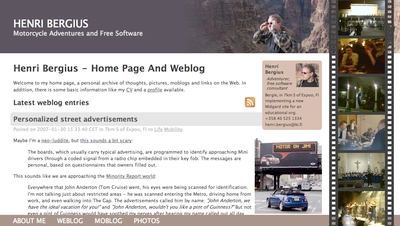
This is the latest iteration of my home on the web. I’ve had a website since sometime in 1994, and under this same “iki” address since 2001. This latest design was actually made in spring 2006 after our US trip, but has been waiting in mothballs for the right moment.
Nemein delivers browser based free software solutions. Our clients include some of the leading advertisement agencies in Finland as well as major private and public companies. Nemein is looking for a junior consultant to join our Midgard deployment team.

This winter's Midgard meeting has been a bit different than the usual fare. Instead of running the session only in one place, the meeting already started last monday with work on the new replication framework and a dinner with Helsinki-based Midgardians. Then after the week spent on replication we packed our team to a Land Rover and drove to Linköping...
Midgard has had replication capability since late 1999. First replication was handled with the Repligard command-line tool. Then in 2005 we got the Java-based Exorcist tool that was able to do cross-CMS replication. But both of them suffered from being slightly external of the normal Midgard environment. With Midgard 1.8.1 there is now an integrated Midgard Replicator system that provides...
Microformats are a cool way of making web content machine-readable. Since the formats rely on classes, they also ensure the content has all the hooks needed for good CSS design. Microformats can be understood by aggregators like edgeio and consumed with software like Firefox 3 and the Tails extension for Firefox 2. We have been introducing Microformats to all sites...
Resource booking component net.nemein.reservations has been finally converted to MidCOM 2.6 technology. The component allows users to browse available resources, their reservation calendar and make new bookings. Default usage scenario for the component was meeting room bookings, but the component has been designed so that adding other types of resources like cars or cabins is just a matter of editing...
N800, the successor to Nokia’s 770 Maemo-powered Linux internet tablet was apparently unleashed yesterday by CompUSA. While Nokia’s site is still quiet on the new device, there are already unboxing pictures out there. I’ve been using my 770 quite actively as a mobile internet terminal since I got it in February last year. While the software is occasionally buggy, it...
2006 is about to end and the blogosphere is filling up with wish lists and plans for the coming year. Before I go to Saint Petersburg for the new year celebrations I wanted to write something about how I see 2007 for the Midgard CMS project. Software-wise, 2005 and 2006 have been good years for Midgard. MidCOM established itself as...
MidCOM 2.6.0 has been out for a while, with 2.6.1 scheduled for today. While that branch has now been stabilized for bug fixes and small tweaks only, there is work going on in the SVN trunk, or what is to become MidCOM 2.7.

Now, this one has been on my TODO list for a while:

Like in some earlier situations, I’ve again gotten a bit backlogged with publishing my photos. In any case, here are some new sets on Flickr:

I was discussing this IT problem at ESEEI today: Mamona, or Castor oil plant is an oil-producing plant that can be grown in relatively dry areas. Farmers of dry areas in the state of Paraná, Brazil are generally relatively poor. Petrobras has a process where Mamona seeds can be used to produce biodiesel fuel. The IT problem related to this...
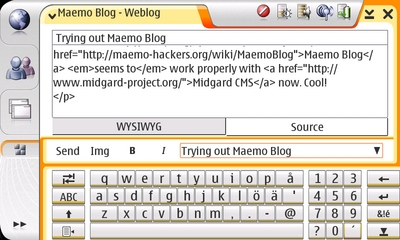
As reported by Inz, Maemo Blog seems to work properly with Midgard CMS now. Cool!
I’ve today upgraded the Midgard development environment on my MacBook to a more reasonable software setup:
The GNOME desktop community has been evaluating different CMS options since July. TikiWiki, Drupal and eZpublish were eliminated because of missing features, and the final was between Plone and Midgard CMS.
One big idea we’ve had with OpenPsa has been supporting various standards and Microformats to make the user experience richer.
Midgard’s support for GeoRSS is solidifying with the auto-probing system in OpenPsa and the latest release of org.routamc.positioning.
Midgard 1.8.0 is out, and so according to the roadmap we can finally start getting rid of legacy Midgard1 features to get into the nice, clean slate of Midgard2.
Maemo, the open source mobile device platform developed by Nokia is switching its web infrastructure to Midgard CMS. Ferenc Szekely writes:
Inspired by the PHP Eats Rails for Breakfast report, I’ve registered Midgard CMS at Ohloh, a service tracking code contributions in various free software projects.
I was one of the people interviewed for Jyrki Wahlstedt’s essay Managing Changes in Collaborative Innovation Networks. It deals with how innovation networks like free software projects communicate:
net.nemein.ping was the original experimentation ground for MidCOM’s content update notifications support. However, it had since fallen into disuse as it waited re-implementation using MidCOM’s at service to ensure pings are run asynchronously.
I’m spending some time this week on a specification workshop in the countryside. Mostly we’re looking at integration points between Midgard, Gforge and Doxygen to provide a complete open source project collaboration environment.
I drove from Turku to Helsinki early in the morning with a Land Rover that didn’t have headlights. Since then have been hunting performance issues in latest beta of MidCOM - the component architecture used by Midgard CMS.

September 22nd is the OneWebDay. It is a day when users of the World Wide Web are encouraged to show how the Internet affects their lives. The purpose of the event is to globally celebrate online life.
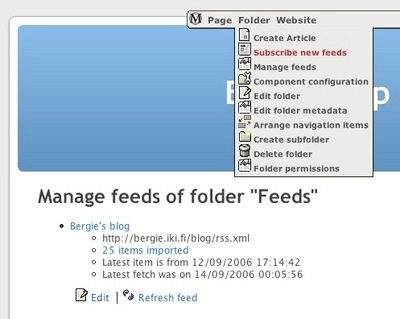
Midgard CMS has had an integrated RSS and Atom aggregator for several years. It has been used for both bringing simple news feeds to portal sites, and for Planet-like large-scale blog aggregation.
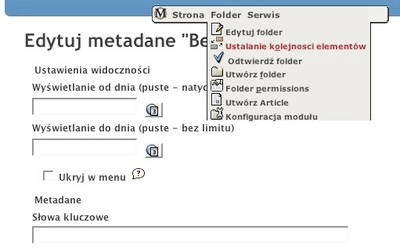
MidCOM, the component framework used in Midgard CMS is rapidly approaching 2.6 stable, and a lot of minor improvements are trickling in. These include a drag-and-drop way to reorganize navigation items and a new view listing MidCOM contributors.

I’ve just committed the new login screen styling for Midgard CMS into the SVN repository.

Public Geo Data is sending an open letter to the European council of environment ministers to request that the access to geographical databases would be opened to the public. While some data is open and available, we’re still far behind the US in this issue.
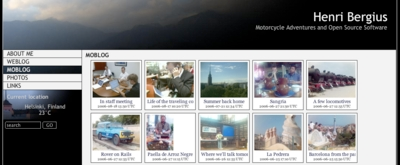
My moblog hasn’t been updated since GUADEC last July, and some relatives have already been asking about it. The reason why I haven’t updated is that I switched to the Nokia N90 camera phone, and the email format it uses makes Mail_mimeDecode fail.
Most Midgard components use a tool called Datamanager to abstract data storage and content editing. With Datamanager, site builders can define multiple schemas to be used at different areas or for different page types, each with a different set of content and editing fields.
I love the things LiveJournal is doing with Jabber:
Midgard CMS differs architecturally quite much from the typical open source CMSs in that its core is written in C on top of the GLib library.

Since we have some new members in the team, it was time to grab some new Intel MacBooks. I also decided to switch and recycle my 12” PowerBook to another team member.
OpenPsa2 source code has now been moved to the Subversion repository used by MidCOM. Since OpenPsa is now a pure MidCOM component system this should aid in cross-project collaboration.
Thanks to the efforts by Solt and Piotras, we finally have the MidCOM, the Midgard Component Framework running on top of PHP 5.1.
Late July sees a lot of changes in the Midgard Components Framework project. Since its appearance in March 2003, MidCOM has established itself as the standard way of building and managing Midgard CMS sites.
The GNOME desktop project from which Midgard also gets a bunch of libraries is now choosing a CMS for its website.

Summer holiday is now over, and as Tigert put it, we made it to Gibraltar.

We held the Feeds, Synchronization and the Free Software Desktop talk with Tigert today. Despite the Fluendo party the night before, there was a quite good crowd in the old Museu Balaguer library.
Tony Byrne from CMS Watch noted the recent advances in Midgard based on yesterday’s 1.7.6 release:

I’ve committed the first working version of Midgard’s geopositioning system into CVS today. The library makes it really easy to add location information to users and objects, and to find things that are close to each other.

MidCOM datamanager allows you to have multiple page types, or schemas used in a folder. The schemas can provide different editable fields and different styling.

We spent the last two days driving from Helsinki to Poznan, Poland for the Midgard Developer Meeting. This proved to be a good field test for Maemo 2.0 as we needed to instruct people back home about some project details using Google Talk.
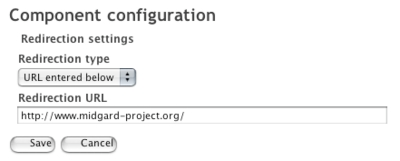
MidCOM has a centralized system for serving navigation information called Navigation Access Point. Typically the navigation UIs on Midgard-powered sites are dynamically constructed using this information.
Growl is a very nice notification system for Mac OS X. It displays bubble-styled messages on the screen about various events like new instant messages or emails. We were looking for a new user interface messaging system for the Midgard web toolkit and decided to model it based on the Growl concept:
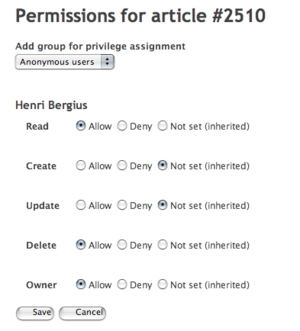
MidCOM has had a comprehensive Access Control Lists system since last summer, but its usage has been hindered by lack of an easy management tool. That is now fixed with the first stable release of the Midgard ACL editor.

Piotras remarked that the process started in East European Midgard Developer Meeting three years ago to build a Midgard 2 on top of the glib library is now a reality.
Arttu and others at the office are now tuning the Midgard UI with these goals
Thanks to Jyrki Wahlstedt there is now a new way to install Midgard CMS on a Mac: DarwinPorts.

This year’s GUADEC will be held in Catalonia on Jun 24th - 30th. We’ve left a proposal with Tuomas, so I hope I will be able to attend.
The Midgard mailing lists have been offline for a while because their hosting provider has been having some issues. To fix the problem we decided to move from regular email lists to an online forum powered by the net.nemein.discussion component.
We just ported a portal containing tens of thousands of documents from Abako Stato to Midgard CMS. Content conversion was done using Exorcist as usual.
The MidCOM PEAR channel has now been upgraded to the Chiara_PEAR_Server version of PEAR channel serving. The upgrade went mostly painlessly following Greg Beaver’s instructions.

The Midgard booth is now all set up in EclipseCon 2006 Open Source Pavilion. If you read this, feel free to drop in to booth 416 and enjoy an M candy and some Midgard talk.

There is a post on Tapestry plug-in weblog analyzing the participants of the EclipseCon Open Source Pavilion. The post is a bit doubtful on Midgard’s participation:
It seems the MidCOM PEAR channel is incompatible with the PEAR 1.4.7 release. When you try to discover the PEAR channel you get:

Tarjei was experiencing problems with MidCOM’s cache system:
Donald Smith writes:
With these two recent conference invitations, it looks like the spring will be extremely busy.
Since completing MidCOM’s PEAR 1.4 packaging the main remaining issue of making MidCOM installation user-friendly has been setting up a channel. This is now done, and MidCOM 2.5 can be installed in the following way:
After a bit of discussion and goading from the PEAR community, we decided to package MidCOM for the package.xml 2.0 format and only support PEAR 1.4 or newer.
I’ve spent some time yesterday and today rewriting the Midgard Wiki software to the new MidCOM architecture. Major changes include:
We spent the New Year’s Eve at our favorite rock star’s place having sauna, and welcoming the new year with Pikkuoravat, Verka Serduchka and Sovetskoe Shampanskoe. Globalization was really showing through, with SMS messages arriving in several languages and from several different time zones. Some samples:
We have recently been contracted to develop a new workflow engine on top of OpenPsa to support different pharmacovigilance and drug regulatory processes from the viewpoint of a drug manufacturer.
Slashdot has an interesting editorial by OSDL’s Dave Rosenberg on why Open Source business must own its Intellectual Property:
When trying to PEAR-package MidCOM components with our new pear-package.php utility I ran into this error message:
As a way to resolve the style engine dispute in the Midgard community, I asked Jukka to arbitrate. He posted his proposal for the Midgard Style Engine V2.0 yesterday, and after a bit of discussion it entered mRFC process. The proposal was accepted today with 7 +1 votes from the developers.
It is December now, and my RSS reader is filling up with predictions for the year 2006. Here are snippets from some good ones:
Edi ran into some issues with link prefetching and MidCOM administrative interface:
Codey from Indian Express is wondering about aesthetics and sensibilities of CMS:

I had my Midgard tutorial in Fórum GNOME today, and it turned out to be a near disaster. English is not very widely spoken in Brazil, and my audience couldn’t really follow my talk. Luckily GIMP developer João Bueno came to the rescue and acted as an excellent Portuguese translator. This saved the session and enabled me to have meaningful...
Arttu was exploring the advantages and disadvantages of the different ways of serving images and other remote files connected to a Midgard CMS layout. At first he switched from the legacy Aegir attachment server to the MidCOM attachment server:
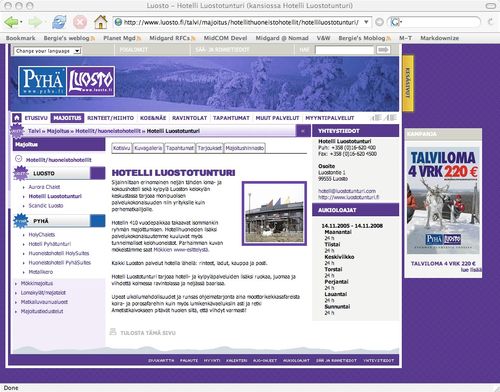
Pyhä and Luosto, two skiing centers in Lapland are now powered by Midgard CMS. Their websites are portals containing both general travel information and the sub-sites of hundreds of local hotels, restaurants and other businesses. The portals were designed by advertisement agency Linnunrata and mainly built by Arttu Manninen from Protie. The Midgardization was supervised by Nemein. Hosting for the...

I’m traveling next week to the Fórum GNOME conference in Curitiba, Brazil. The actual conference is held together with Latinoware Mercosul on November 26th - 27th. My two sessions in the event are: Saturday 26th: 14:00 - 18:45 Midgard CMS - four hour tutorial for building your first Midgard-powered web site Sunday 27th: 16:00 - 17:00 Digital Business Ecosystem -...
Tigert has been sketching some Tango-styled UIs for the new Aegir admin interface of Midgard CMS:

The budgetary question for Air New Zealand’s Intranet seems to be:
DENIM is an interesting, BSD-licensed desktop application from University of Washington. It allows web developers to sketch site and page structures easily with a stylus. Pages can be interlinked, and contain operable components like forms.
Zend, IBM and others have announced a collaboration project to create a Zend Framework using the following mission statement:

Here are the Midgard CMS slides we presented to two major potential Finnish customers on friday:
If you get this error message when trying to start Apache, then you’re out of semaphores:

This weekend is being spent in the Midgard developer meeting hosted by Anykey Solutions in Linköping, Sweden. Besides the ferry Suicide Tequila episode reported by Edi, the time has been both productive and fun. Happened so far: Tarjei ran a pretty interesting demo and presentation on the Aegir 2 project. It seems that once the object browser is done, we...
net.nemein.calendar is the new default calendar in Midgard CMS. It replaces the old de.linkm.events component with several clear advantages:
We’ve gotten several problems of memory leaking with MidCOM used with PHP4 and Apache2 on both Fedora and Debian platforms. At first memory leaks on Midgard 1.7 were suspected, but after extensive testing this theory was discarded.

Day zero: In transit
WebProNews has a story on how the future of web design is content management:
Torben published a new MidCOM feature called watcher yesterday. It enables Midgard CMS components and libraries to register to receive notifications about changes to Midgard objects of different types.
Content Management market analyst CMS Watch has released its Vendor Kudos and Shortcomings of 2005 list. Midgard CMS gets honorable mentions in two categories:

Photon, Jonathan Younger’s nice photoblogging plugin for iPhoto was released under LGPL last thursday. The tool officially supports Wordpress, MT, TypePad and Blojsom, but actually posts using the standard MetaWeblog API that Midgard also supports.
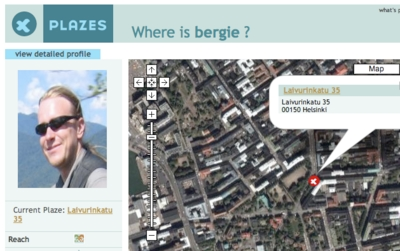
I’ve posted thoughts about using location information on the web and my blog has been associating position information and weather on city level into all documents there since last December. However, this data isn’t very useful yet as such. As the city-level information doesn’t contain coordinates, I can’t:
The Mac OS X packages of Midgard made by Robert Guerra were released on August 15th. Since then it has been listed by both VersionTracker and Download Squad. Six hundred people have already downloaded the 500 meg disk image containing both Midgard CMS 1.7 and Fink.

Our development server just died today. This will mean all OpenPsa development is stalled until Rambo gets the new hard drive and Debian installed.
Because of the dead development server I had a bit of downtime today. To compensate for it, I decided to finally port the elegant Kubrick template to Midgard CMS.
AIS, the Authoring Interface System in Midgard CMS is now getting a new look. The tables and old HTML are now gone, replaced by much more streamlined XHTML and CSS.
While not everybody agrees, it really feels like the Midgard Wiki way of generating documentation is working. The idea was to make the documentation more consistent, and to lower the barrier of submitting new content.
Midgard 1.7, the first release sporting Midgard2 features like MgdSchema and Query Builder was released today. To celebrate this, I made a new design for the website, following the “Prepare for the New Day” slogan:
I added Kai Blankenhorn’s FeedCreator PHP Class into the MidCOM CVS yesterday as purecode component de.bitfolge.feedcreator. The library is already being used by the Midgard Wiki for its RSS output of latest modifications.
The documentation on the Midgard Content Management System is now moving to wiki format. This will make it much easier for people to contribute documentation into the Midgard site instead of posting it in their own blogs or documentation and tutorial sites.
Andy Smith has noticed he doesn’t like frameworks:
Focus of the Midgard developer community is swiftly moving to the Midgard2 architecture, and this means that changes will be coming to the rest of the framework.
I’ve today integrated John Coggeshall’s Tidy PECL extension into Midgard CMS. This means that all WYSIWYG-edited content should now be stored in proper, cleaned and indented XHTML.
There are several places in OpenPsa where persons are displayed in some list: Search results, campaigns, buddy lists, project participants, etc. To make them more informative, I’ve now implemented a contact widget library that can be used anywhere in MidCOM.

Finally the summer has started here in Finland and it is warm enough to spend time at the summer cottage and swim in the lake. At the same time, my trusty Triumph Legend is again running after its starter problems. Big thanks to Mp-Asennus.com, especially as they installed the Kawasaki starter ahead of schedule and under budget!

The Finnish Broadcasting Company launched today the website for Itse Valtiaat, a popular political satire cartoon series. The site user interface has been built with Flash to provide an interactive and animated world familiar from the series.
The number of components and libraries in MidCOM is raising rapidly, especially as both Aegir and OpenPSA are being rewritten on it. As now all MidCOM packages ship in the distribution, this causes lots of unnecessary clutter on systems.

Looking at the recent developments in Midgard CMS space, it looks like the MidCOM, the Midgard Component Framework developed by Torben Nehmer has finally established itself as the default Midgard development framework for PHP.
Following Kaukola’s Support ticker viewer and kindly financed by our friends at Protie, we now have a Midgard CMS component that allows customers to view and approve OpenPSA Projects hour reports.

Russian Open Source Forum was a gathering of local software companies, Open Source developers and government IT people that brought together about 1500 participants. The event’s celebrities were Jon “Maddog” Hall from Linux International and Larry Wall, the Perl creator.
I’m leaving on tuesday to speak in the Open Source Forum in Moscow, Russia. The event will be held in the Radisson SAS Moscow from April 27th to 29th, and I will be back in Helsinki on 30th. My talk, TownPortal: IT Village Project for Danish Communities is scheduled at 5pm on thursday. I will talk both about the actual...

Midgard Query Builder
We’ve just announced something interesting, an expansion to the Georgian market. This new development follows the franchising strategy I’ve outlined earlier. This should produce some very interesting business opportunities, and let us focus on internationalization even more strongly than earlier. We already have a translation of the website and OpenPSA to Georgian, with Midgard CMS localizations to follow… Welcome to...
Taya and Lasha from Nemein Georgia were coming to Helsinki to attend some Midgard training and the MgdSchema Workshop this week. As Finland has no representation in the country, they applied for schengen visas in the German embassy. As planned, they flew to Moscow to take their connecting flight to Helsinki, but were refused to board. The reason, as it...
Midgard 1.7 alpha release is now under work, and will ship the Midgard Site Wizard with a new default way for creating websites. The Site Wizard enables developers to create layout templates that can be reused and customized when creating new websites. When a user runs the Site Wizard to create a new website, they will be presented with a...
The friday started with Esther Dyson’s breakfast talk about the importance of Internet for philanthropy and human interaction. After that we had the Online Publishing and Content Management with Open Source Software session chaired by Ryan Ozimek. Ryan and Usha Venkatachallam of Beaconfire opened the talk by introducing the audience to Open Source Content Management in general and then we...
The first day of Nonprofit Technology Conference 2005 started with a breakfast session where Mena Trott of Six Apart was telling about community building with blogging tools. Her examples included Save Karyn and the Star Wars Kid raising money through popularity in the weblog world.
I helped Tigert to install Midgard yesterday, and the project was
quite non-trivial. The main issues were:
Here are short notes on how I installed the MidCOM indexer for a client. The client has an intranet site running on Midgard 1.6 and MidCOM 2.1.0 on Red Hat Linux 7.3. Install MidCOM 2.3 Download MidCOM 2.3 and install it: # cd /usr/local/share/midgard/ # wget http://www.midgard-project.org/midc...1c9/MidCOM-2.3.0.tar.bz2 # tar jxvf MidCOM-2.3.0.tar.bz2 # ln -s /usr/local/share/midgard/MidCOM-2.3.0 /usr/local/share/midgard/midcom Install the PHP Compat...
We’ve today moved the MidCOM search tool into production together with the development release 2.3. Some statistics from Torben:
Midgard CMS has now support for the Markdown text-to-HTML conversion tool. Markdown is an useful tool for writers that allows creation of web content with a simple text syntax. Markdown is available in MidCOM's CVS repository as datatype_markdown. The tool utilizes Michel Fortin's PHP Markdown parser. To use Markdown for a content field in your MidCOM site, edit the datamanager...
Nemein is sponsoring a contest to design a new user interface to the Midgard Open Source Content Management System. The winning designer will receive an iPod Mini portable music player.
The Midgard style templating system was designed back when site layouts were still mostly in-line HTML tables. As such this caused some problems with the new standards-based school of web design, as there it is desirable to place the layouts into separate, linked style sheets.
Finland is a country with three official languages, and many organizations here want to provide their websites in multilingual format. While Midgard CMS supports storing multilingual content in same content tree, this is still not widely used. A far more common strategy is to use language prefix URLs. With language prefixes each translation of a site has its own content...
Lots of Content Management Systems strive to provide meaningful URLs. With CMSs meaningful URLs usually mean mapping the internal content structure of the system to a filesystem-like tree hierarchy, which has the downside tying the URLs into the site structure. When the site structure is reordered the links can easily be broken. While sensible CMS deployments set up redirectors for...
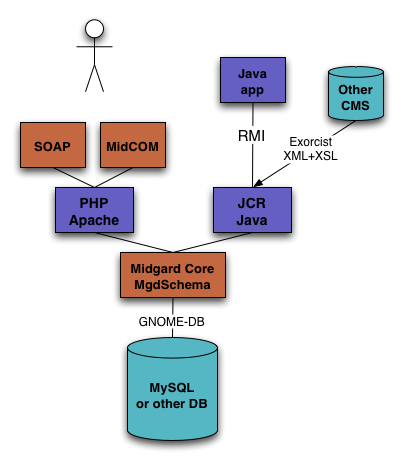
We had a pretty interesting meeting with Jukka Zitting in Ilves last night. Jukka is the original author of the Midgard CMS, and has been on hiatus from the project since 2000. Now he has started his own company, Yukatan with plans of providing JCR-based integration services for Content Management Systems.
This week I've been working on revising the Midgard discussion forum component to a usable shape. While the old version was OK when dynamically loaded as a comment system for blog postings or photos, it lacked the functionalities needed to make it a real forum.
Yesterday I got the mRFC 0007 compliant Site Creation Wizard for Midgard CMS into feature-complete state for phase one.
This enables Midgard users and developers to test and comment the tool while I refine the user interface and help texts. Here's a screenshot tour of the current wizard
After quite some planning, I've today started coding a site creation wizard for Midgard CMS. The goal of this wizard is to make the Midgard learning curve less steep for new users and the site creation process more efficient. The specifications for the wizard can be found in mRFC 0007: Midgard Site Creation Wizard.
Hot on the heels of my previous Midgard CMS tutorial, "Creating custom navigation with MidCOM, here is a new one about adding categories to a Midgard-powered blog. I've written this in response to Robert Guerra's questions. Midgard CMS contains a powerful PHP-level data abstraction layer called datamanager. With datamanager it is possible to freely modify the content fields and editing...
I really like this comment in CMS Watch's latest Web Content Management Marketplace article:
Today we secured funding from two clients for developing an integrated search engine into the Midgard CMS. The project will be undertaken by Torben Nehmer and will also improve Midgard's metadata capabilities.
Based on some chats today and yesterday with Privaterra and others, here are couple typical new Midgardian gotchas: Fatal error: Allowed memory size of 8388608 bytes exhausted when trying to create a subtopicCurrently MidCOM's component listing used in the "Create subtopic" dialog needs quite a bit of memory. While solution is being planned, the easier way is to edit your...
One frequent question I see on #midgard is how to customize the default navigation options shipping with the MidCOM template site. In my opinion, there are two options: Either stick with the existing navigation styles and customize via CSS, or roll your own in PHP.
There has been some discussion on the Midgard IRC channel comparing Midgard CMS to the WordPress blogging system. Adam Douglas commented:
I've today updated my blog to display the location the post was made from. The location is linked to blog postings, photos and moblog entries based on their timestamps. This is done by maintaining a database of locations with the times I've been in them in Midgard CMS. To report a new location I simply send an SMS containing the...
I've today upgraded the RSS and Atom news aggregator of Midgard CMS, net.nemein.rss to utilize the latest Magpie RSS release. The main new feature in Magpie 0.71 is support for multiple character encodings. This means that news aggregators like Planet Midgard can now safely read feeds whether they are in UTF-8, ISO-latin-1 or some other encoding and trust that they...
Alexey Zakhlestine has designed two new "Powered by Midgard" buttons users can display on their site to support the CMS project:
For years there has been talk of getting Microsoft Windows supported in Midgard CMS. Now the situation seems to be progressing, being lead by Daniel S. Reichenbach from Best off. As most production websites are run on Unix, why are we interested in running Midgard on Windows? The Motivation part of mRFC 0011: Midgard on Windows Platform replies:
Testing the new filesystem-enabled version of MidCOM is now easier than ever, with the new forked and fs-enabled version of midcom-template: Get fs-midcom from CVS Install the new fs-enabled midcom-template from CVS Install fs-midcom under /usr/share/pear/midcom Note: you can change this path from /midcom-admin/settings Symlink the static directory to your DocumentRoot. For example: ln -s /usr/share/pear/midcom/static /var/websites/www.ruutukuningatar.net_80/html-data/midcom-static ...and you're done....
Session notes from Linköping Midgard Gathering by Henri Kaukola. The problem of the Open Source desktop systems is that they are designed only for one user per time. There's very little information sharing. Integration between server software and desktop world is the key to Open Source world domination. Document management system must support WebDAVNews pages must provide RSS syndication and...
MgdSchema is the new way for defining Midgard's object types in XML being worked on by Piotras. So, why are we sponsoring this development? Here are some blue-sky points brainstormed in our hostel during the first evening of the Linköping gathering:
We're now in the Midgard Gathering in Linköping. Since Sweden has been too far for many Midgard community members, we're trying to make the event as connected as possible. So far it is possible to follow the event live from two web cams: The web cams are available here and here. To see the image log in as guest/guest. In...
Here are quick notes from today's MgdSchema discussions with Piotras. The idea is to define Midgard objects in XML the same way as Repligard doesCurrent status of MgdSchema is an app that parses the schema and displays it as debug infoThe object definitions will be reloaded every time Midgard is startedMgdSchema will provide the object types as GObjectsThe GObjects are...
NemeinQuiz is an online exam tool originally developed for Pharmaceutical Information Centre for their pharmaceutical sales courses. We published the package as Open Source with some quick setup instructions. While setting up a Midgard-powered site for the Student Union of Helsinki School of Economics (KY), I decided to take another look at NemeinQuiz to see how well it would integrate...
On thursday afternoon the Nemein team together with Edi from Dialogi will pack into Rambo's Land Rover and take the Midgard-powered ferry to the Midgard Gathering in Linköping, Sweden. The meeting agenda has been available for a while now. To complement it, here is my list of talking points: MgdSchema is the new object abstraction back-end for Midgard proposed by...
The filesystem migration of the MidCOM component framework has now progressed enough that it actually powers this site, as reported by the HTML generator meta tag: Midgard/1.5.0/SG MidCOM/1.9.0+cvs.2004.11.05 PHP/4.3.9-1 If things are going this smoothly, the following will only be needed before we can replace the old MidCOM 1.4.x tree with the mRFC 0006-compliant version: The rest of the components...
After much hard work by Piotras and the rest of the Midgard team, Midgard 1.6 is now the stable release of the Midgard CMS. This is very cool since it brings lots of new features like MultiLang and datagard available for the Midgard population. The release announcement says about the new data package: The revised Midgard-data package provides an out-of-the-box...
Planet Midgard is the blog aggregator displaying what's going on in the Midgard community. Planet Midgard is now running latest version of net.nemein.rss aggregator, meaning a bunch of new things: Support for feeds in Atom format (previously we could aggregate only RSS feeds)UTF-8 support, meaning that we can now aggregate blog postings in non-western characters (especially Russian seems to be...
Based on my earlier blog entry, there was an interesting talk in OSCOM 4 about CSS Naming Conventions. My after-talk discussions with Thorsten Scherler led to development of OSCOM specification for CSS Naming Conventions. I've now used the XHTML skeleton from the specification for some websites, and have been generally quite happy with it. Here is a simple Midgardization of...
For years Midgard application development has been constrained by the fact that most of the programming work has had to be made through a browser window. Now there is a solution through WebDAV. Earlier usage of better editors has been possible through two slightly hacky solutions: PHPmole is a nice IDE for PHP. However, it is written using the PHP-GTK...
Midgard 1.6.0rc2 was released earlier today. I decided to try it on my local iBook. Most of the stuff seems to install just like in my earlier installation, except that some packages have been renamed. midgard-lib is now midgard-core and mod_midgard is now midgard-apache1. First problem was that I tried to install Midgard to a custom prefix, /usr/local/midgard, and midgard-config...
Categorization works quite simply; the MetaWebLog API connector for the de.linkm.newsticker looks at its schema definition, and if it finds specific field definitions it will enable categorization. The two options here are: Multiple categories per post: "categories" => array ("description" => "Categories","datatype" => "multiselect","location" => "parameter","multiselect_selection_list" => array ("cat1" => "Category 1","cat2" => "Category 2", ), ), Or single category...
His notion might have backgrounds in only looking at the projects listed on OpenSourceCMS.com, which only lists lightweight, mainly PHP-based content management systems, not any of the heavier-duty ones. However, it is true that most Open Source CMSs are not that good. A major cause for that is duplication of effort. Everybody wants to build their own CMS and not...
This blog has now been successfully converted to the UTF-8 character encoding. This enables using non-western characters in any part of this site. НЕ РЛОХО! This was all made possible using Torben's handy MidCOM UTF-8 HOWTO. Please report if you note any issues. Note: Newsticker's MetaWebLog API support doesn't seem to work 100% reliably on UTF-8. ecto seems to support...
Inspired by the public betas of MarsEdit and NetNewsWire, I looked up an old MetaWebLog API support patch I had made for the blogging and news ticker tool of Midgard CMS, de.linkm.newsticker. I modernized the patch a bit and committed it to MidCOM CVS. This means that all Midgard CMS installations using the new version will provide support for desktop...
The "messaging device" has a crappy CIF camera, but I think that still the ease of taking photos helps to make my site more live.The procedure for posting a photo is the following:Take a photo with the cameraSelect "sent" from the options -> "send as MMS"Type the photo caption to the MMSSelect "send as email"Then the photo gets sent via...
Current situationTo those unfamiliar with Midgard development, Midgard Framework itself has been written as a C system library and a PHP extension. The Framework provides services like authentication, templating and content storage. The actual Midgard applications are written on that foundation in PHP and stored in the Midgard database as pages and "snippet" objects.MidCOM functions as a component system written...
The segfault seems to be triggered on pages that have multiple mgd_auth_midgard() or mgd_unsetuid() calls. In most cases the crash happens only after Midgard request has completed, but before output has been sent to the browser, as reported by Torben.In OpenPSA Personnel this happens when administrator modifies a user record. There we have worked around this by simply exiting the...
To make implementing UTF-8 in Midgard easier in the mean while, Torben Nehmer has posted a handy UTF-8 with MidCOM guide.More information about internationalization in Midgard can be found from Midgard Documentation.Of course, even after Unicode is the default encoding in Midgard we will have to go through many MidCOM components to ensure they conform to test suites like Sam...
I wanted to ensure that wouldn't be a problem on sites built with Midgard CMS and MidCOM. On an IRC discussion with Torben Nehmer, I pointed him to Alexander Alapite's Conditional GET support library for PHP.However, it looks like this is not an issue, as MidCOM already supports conditional GET if its server-side caching system is enabled:
The SMSs are sent to an old Ericsson R520 mobile phone which is connected to a Linux box running gsmsmsd from gsmlib. New SMSs are forwarded to Routa MC as emails, which are imported into Midgard using fetchmail and the OpenPSA mail import script supportmda.pl.
Then the SMSs are handled by a Midgard page which has the following code:
One reason is that PHP provides a lightweight way of building efficient web applications. Russel Beattie writes: Once again I ask - why is Java web programming not keeping up? Why are Java web projects so bloated (I've got 5+MB of .jar files in my current web project and I think more are coming). Why are the pages so difficult...
The RSS feed is courtesy of the Midgard-User Yahoo! Group.Direct URL to the Midgard-User RSS feed is:http://rss.groups.yahoo.com/group/midgard-user/rssThanks to Dave Winer for notifying that Yahoo! Groups now provide RSS feeds for all public group discussion lists.
WALHI is the Indonesian Forum for Environment. Their CMS implementation will be modelled after the Midgard solution deployed by The Wilderness Society Australia.It is very nice to see NGOs deploy Open Source CMSs, or more specifically Midgard. These organizations have much to gain from efficient communications, and Open Source is the cost efficient way to accomplish that. Open Source is...
The form styling templates provided in the tutorial utilize two HTML form-specific elements for defining the structure of the form: label and fieldset.
rapid release scheduleregression testsdo one thing wellavoid over-designa central visiondocumentationavoid standardsismup and running in ten minutes or less!developer responsivenesseasily update-able wiki pages

The 5th anniversary meeting will be held in Poznan, Poland. We're going there tomorrow with the whole Nemein team.
Now is the time to get a special Midgard 5th anniversary t-shirt and raise a beer glass for the project :-)
Ximian Build Buddy is a tool for building binary packages for different Linux distributions.
We discussed this trend some days ago with Torben, and came up with several points:Midgard 1.x is starting to show age. The framework was designed back in 1998Code quality in 1.6.0 alphas and in some major modules like Aegir is really badThe competition is getting tougherInstallation is still horribly difficultHowever, even despite of these, we decided there is no reason...
The solution was to use the convert utility from ImageMagick to automatically force all images to RGB color space. However, even after this the thumbnails I generated were ridiculously big (500KB instead of 4KB). After some investigation I noticed that some color profiles had been included to the image files. Again, convert was able to fix this.The options used here...
With the label element, forms would look like:<form method="POST"> <label for="firstname">First name</label> <input type="text" name="firstname" id="firstname" /></form> This would make the connection between a field and its label machine-readable, enabling easier handling for accessibility purposes. Also, this mark-up would be slightly lighter to download that the current <div /> solution. Thanks to Nico for the suggestion. Label resourcesAbout.com HTML Guide:...
It has to be said that Daniel's team has made amazing progress with the administrative interface. The new UI looks very slick, and Tony Lee's logo design fits it very well.The user interface is also using our NemeinLocalization library. As soon as the language strings are included in the build I will translate them to Finnish.In addition to translations, the...
The discussion on the matter continues on Slashdot thread "Making Things Easy is Hard".With Midgard, there are several major issues affecting usability:Installation is horrible: solution would be to provide prebuilt packages for popular Linux/Unix platformsSite setup is difficult: we should integrate sitegroup creation, host creation from template, style creation, site initialization and VirtualHost setting into one simple "Create website" dialogContent...
"...automated business systems are being retrofitted to generate data in RSS format. For example, Triple Point uses StarTeam for source control and release management... In the past, developers were required to produce email announcements of each source code change; now that process has been automated via RSS."

OSCOM’s president Michael Wechner is one of the Twenty CMS Leaders to Watch in 2004 in a list published by CMSWatch.
David Schmitter and Henri Kaukola will be attending the 3rd OSCOM Sprint in Zurich on Jan 23rd to work together on the MidRepository workflow module for Midgard.
FreeDesktop.org has started a new project for evangelizing and documenting proper Unicode support in free software. It’s called Project UTF-8.
Linux Center (HK) Ltd. has moved the popular Nadmin Studio content management product and its successor, Aegir CMS under the GNU General Public License (GPL). The GPL licensing provides users rights to use, modify and distribute the software as long as the source code is kept available and modifications to the application given back to the development community. The licensing...
David Schmitter from Dataflow in Switzerland has now released version 0.9 of MidRepository, a versioning and workflow system for Midgard.
Martin Langhoff’s OSCOM 3 presentation.
Tony Byrne’s OSCOM 3 presentation:
TownPortal is an Open Source portal package based on Midgard and MidCOM. With TownPortal, local communities can easily manage their public web information, and provide web services for small businesses, clubs and educational institutions in the area. The local organizations gain a simple Content Management interface for managing their basic
information, news and event calendars.
Discussing on how Open Source software might still amount to similar customer lock-in as proprietary systems
Essay introducing the key advantages of the MidCOM platform.
Freshmeat has an interesting editorial titled Too Much Free Software dealing with lack of standardization and “not invented here” syndrome in the Free Software / Open Source community causing appearance of multiple versions of same software.
SaM Solutions and Nemein added NTLM Single Sign-on support to mod_midgard I’ve finally added NTLMSSP over HTTP support to mod_midgard (preparser) in CVS. It is pretty isolated from other code but you need to recompile libmidgard/mod_midgard/php module as server config struct in apache.h was changed to include NTLMSSP-related configuration. You need to do it only if you will use libmidgard/mod-preparser...
There is a thread on Midgard user list about tuning Midgard to support over 100,000 page views per day.
OSCOM is an international, not-for-profit organization dedicated to Open Source Content Management. The goal of the organization is to bring together as many great brains as possible to build a network and grow the community of open source content management.
Nemein Solutions, the leading Nordic provider of Midgard solutions arranges a free Midgard installfest on August 14th, starting at 17:00.
I will be speaking in the following seminars and training events during May -June 2000. (16th May. 2000)
It is now a year since Midgard 1.0 was first released, taking the development project into public view.
have posted the initial plans for the Midgard European tour and developer meeting 2000.
The almost-unedited IRC transcript from the first Midgard meeting. (22nd Jul. 1999)
Bergie apologizes the lack of updates to his website and tries to come up with believable excuses for this one.
Bergie switches job and becomes the webmaster of a network security software company.
The News system of Bergie’s website is back online, after being broken by new version of Midgard.
The Midgard Project is born.