VIE 2.0 is starting to emerge
VIE is a JavaScript library that makes RDFa-annotated entities on web pages editable. We started the work towards the next major version of it, codenamed Zart (for Mozart) in a Salzburg IKS hackathon couple of weeks ago.
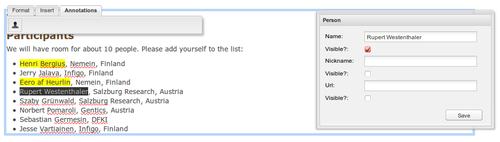
![]()
Yesterday I merged the Zart codebase into the VIE repository. This blog post describes some of the improvements it brings.
VIE now has an instance
For VIE 1.x users the first visible change (and probably the only necessary API change) is that now VIE needs to be instantiated before being used. Singletons are evil, and so we are not a singleton any longer.
So, for existing VIE code, you need to:
var vie = new VIE();
// and then any traditional VIE calls, like:
var entities = vie.RDFaEntities.getInstances('div.article');
console.log("There are " + entities.length + " RDFa entities in your articles");
The VIE 1.0 API can be disabled by passing a setting when instantiating VIE:
var vie = new VIE({classic: false});
Services and VIE
The other big change in VIE is that now the API has been built in a service-oriented manner. This means that for example reading and writing RDFa is just a service you can enable and disable at will.
The benefit here is that we can easily add support for other formats and capabilities without having to touch VIE internals. Thanks to the schema.org situation, Microdata is getting more use, and so at some point we’ll probably add a service for it.
Registering and accessing services is easy:
// Instantiate VIE
var vie = new VIE();
// Pass the service instance and a name you want to use for it
vie.use(new vie.RdfaService, 'rdfa');
// Call a method from the service using the name
// this one would give us the RDF subject of the
// element matched by the jQuery selector
vie.service('rdfa').getElementSubject('div.article');
An immediate benefit here is that we can have two RDFa parsing implementations. If you have problems with our own custom jQuery-based RDFa parser, then you can use the more strict rdfQuery powered implementation instead:
vie.use(new RdfaRdfQueryService, 'rdfa');
Using deferreds
For the new main VIE API we created a sort of a Domain-Specific Language for handling semantic entities. A core part of it is that now all operations utilize jQuery’s Deferred objects. With them you can attach different callbacks to the results of your operation, and they will fire either when the operation completes, or immediately if the operation has already been run.
This gives a lot of flexibility in using the API, and allows us to provide same API for services that deal with the DOM, and services that talk to external APIs like Stanbol.
For example, parsing RDFa from a given DOM element (provided with a jQuery selector) happens like this:
vie.load({
element: 'div.article'
}).
from('rdfa').
execute().
done(function(entities) {
console.log(entities);
});
The chain here is: operation (in this case, load), from service (rdfa), execute operation, then when done, do callback.
With the RDFa service we register Backbone Views for the elements our entities came from, so just like with VIE 1.x, they will update automatically when you change the contents of your entities. But manual writing is also available in case you need it. Here is how it works:
vie.save({
element: 'div.article',
entity: someBackboneModel
}).
to('rdfa').
execute().
done(function() {
console.log("Saved!");
});
In addition to done, which fires if the operation succeeds, you have fail for failed operations, and then which fires regardless of success or failure.
Accessing external services
The new VIE is not just about RDFa. In addition to working with the entities you have on a page, you can also access external repositories of semantic information, like DBpedia.
For example, to find out everything that Wikipedia knows about Salzburg, you could run:
vie.use(new vie.DBPediaService, 'dbpedia');
vie.load({
entity: '<http://dbpedia.org/resource/Salzburg>'
}).
using('dbpedia').
execute().
done(function(entity) {
console.log("This is what we know of Salzburg");
console.log(entity);
});
In browser usage these calls to external services are subject to cross-domain AJAX limitations. A way to work around those is to set up a proxy, and tell the DBpedia service to use that. To do this, pass the proxy URL to the service when instantiating:
vie.use(new vie.DBPediaService({proxyUrl: 'http://localhost:8080'});
With this, all the factual information from Wikipedia will be at your disposal. The size of every city, the height of every mountain. Birthdates and places of birth for famous people. Your web app can do quite a bit with this information.
Finding entities from text
Apache Stanbol is a semantic engine that can extract all kinds of entities from text documents. It can be used for auto-tagging and other things.
Here is how you can use it with VIE:
vie.use(new vie.StanbolService, 'stanbol');
vie.analyze({
element: 'div.article'
}).
using('stanbol').
execute().
done(function(entities) {
console.log("We got the following enhancements for article content");
console.log(entities);
});
Stanbol can tell you what a piece of content talks about. People mentioned, places, concepts. It will also give you the language of the text.
Moving forward
The new version of VIE is still under heavy development. Most of the thngs work, but some details may still change. It is a good idea to start taking a look at it now, but before a beta release at least, VIE 1.0 is the recommended tool to use.
If you already use VIE 1.0 for making your content editable, VIE 2.x will give you a lot of additional power. Enhancements, data queries, namespace handling, and much more.
Thanks to Szaby and Sebastian for helping to make this happen!
Continue reading
Using RDFa to make a web page editable