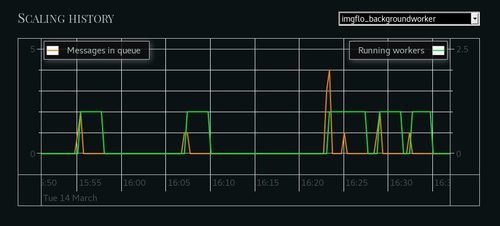
Microservices — an architectural pattern we recommended in our 2012 International PHP Conference keynote — is pretty popular these days. There are many benefits to consider:

As I’m preparing for a NoFlo talk in Bulgaria Web Summit next week, I went through some older videos of my conference talks. Sadly a lot of the older ones are not online, but the ones I found I compiled in playlists:

As mentioned last year, I’m working on a Artificial Intelligence that can do web design. It is called The Grid. Last week I gave a talk at Lift Conference explaining how it all works.
Jekyll is a delightful piece of software. A Ruby application that turns your Markdown and HTML files to a nicely constructed static website. Since the generated site is static, you can deploy and serve it from anywhere with no security or performance concerns. As a matter of fact, this site is built with Jekyll.
The growth of mobile web users is staggering. While some of us have been browsing the web on mobile devices for nearly ten years, most of the world population is only now getting there.
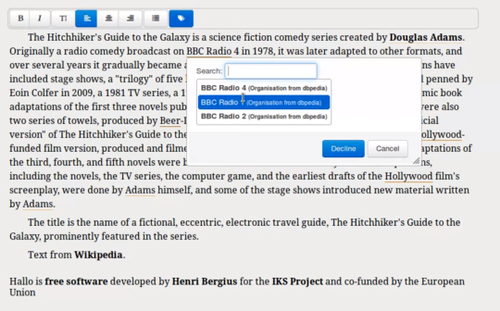
The web is built of links, of pages linking to other resources on the internet. But making those links manually is tedious. This is another area where modern inline editors could do better.
Couple of days ago there was an interesting post on the Dire State of WordPress, talking about the issues developers have when working with this hugely popular content management system:
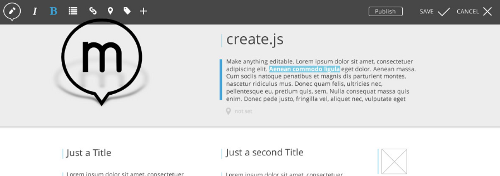
It is now 2013, and the IKS project, started back in 2009 to improve content management systems through semantic technologies, has ended. Alongside Apache Stanbol and VIE.js, the Create.js inline editing toolkit was one of the major outcomes of this European Union funded effort.
Create.js and VIE were recently added to the core of Drupal 8. Just like with TYPO3 Neos, I’ll write a longer post on how things went later.
In a curious turn of events, the Plone team is considering to remove their inline editing feature around the same time when similar features are being added to popular CMSs like TYPO3 and Drupal.

The relation between Create.js and the TYPO3 team goes back a long way. They were present in the IKS event in February 2011 in Vienna where I presented Create for the first time.
Hallo is a simple web-based rich text editor. I’ve written about it before. Even though Create does support multiple editors, Hallo is the one we ship by default as it combines a relatively small size and a permissive license.
We’re now making good progress at releasing the big 1.0 of Create.js soon. The various CMS integrations - from Symfony CMF to TYPO3, and possibly Drupal and many others - have brought us a lot of new features and bug fixes, and will ensure a wide international audience for this inline editing toolkit.
Copenhagen has been the last stop of the current Create.js tour. In here we’ve been integrating VIE and Create into TYPO3 Phoenix, the next major version of this popular CMS.
I spent the last week in DrupalCon Munich followed by FrOSCon, and gave a talk on the Decoupled Content Management story in both.

Last week we at IKS organized a two-day hackathon for developers interested in Create.js, VIE, and in new tools for editing websites semantically.

Our concept of Decoupled Content Management, together with the VIE and Create.js is really taking off. I’ve spent in various conferences this summer speaking about them.
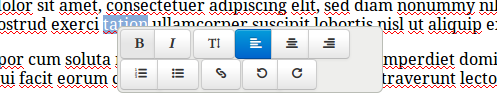
Those who have been following my blog have probably seen the Hallo Editor mentioned in my Create.js posts. But for those who haven’t seen it yet, here is a brief introduction.
Twelve years later, John Allsopp’s classic post A Dao of Web Design is still probably the best argument for Responsive Design:
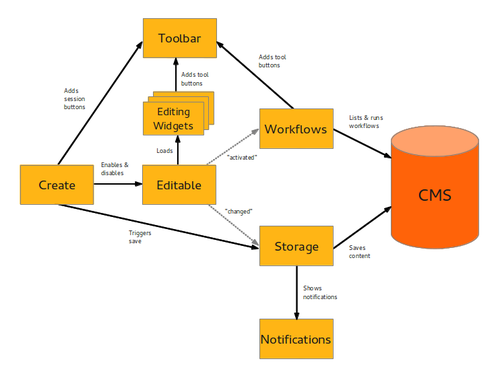
Create.js is our take on modern web editing built on semantic technologies and the ideas of Decoupled Content Management.
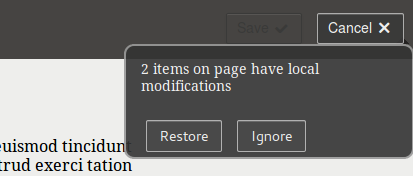
One important part of writing web content is reliability. Since everybody has had bad experiences with their current tools, the current level of trust in web editing tools is low. We’ve all been there, maybe the browser crashed, or the server-side session expired. But suddenly the article you’ve spend an hour writing is gone.
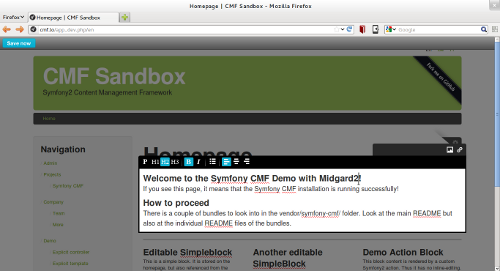
I’ve written about Decoupled Content Management before. As the Symfony Live event in Paris is nearing, I thought to give Symfony CMF a spin. Symfony CMF is a new approach at building PHP content management systems, and adheres quite well to the principles of decoupled CMS:
It seems the idea of Decoupling Content Management is gaining momentum. On the user interface side, many projects have already adopted the VIE interaction framework and widgets from Create, and in the content repository space projects like PHPCR move forward and there are also interesting new ideas like Apache Oak. While much of this has been made possible by the...

I seem to have not blogged about this, but Open Advice, our book on Free and Open Source Software: what we wish we had known when we started, was published last month. The book was edited by Lydia Pintscher and includes essays from 42 authors, many of whom you'll recognize if you tend to go to FOSS conferences. The LWN...
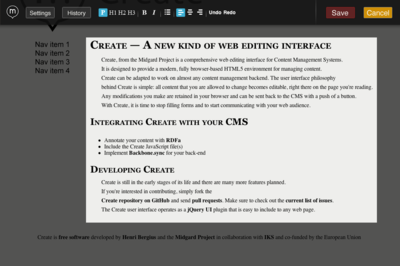
It is again time to write an update on the state of IKS's two main components for the semantic editing part of Decoupled Content Management: VIE is the base semantic interaction library that handles the site's content model through RDFa annotations and Backbone.js synchronization Create is a new kind of web editing interface built on top of that. As the...
As you probably know, we at IKS have been working to decoupled content management through semantic technologies. CreateJS, together with the VIE library provide the user-facing part of this approach.
Create is a JavaScript library that can make any website editable through simple RDFa annotations and Backbone.js. MIT licensed, in GitHub.
VIE is a JavaScript library that makes RDFa-annotated entities on web pages editable. We started the work towards the next major version of it, codenamed Zart (for Mozart) in a Salzburg IKS hackathon couple of weeks ago.
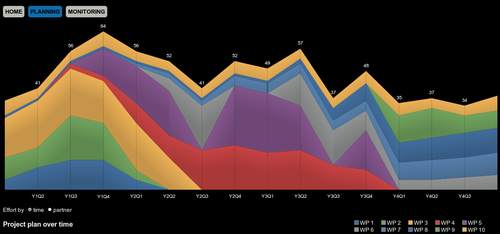
The purpose of business analytics is to find data from the company’s information systems that can be used to support decision making. What customers buy most? What do they do before a buying decision? What are the signs that a customer may be leaving?
I’m getting worried about Google. Long one of the champions of the open web alongside Mozilla, the rise of social networking silos and the app economy seem to have scared them. And like any scared organism, they lash out.

As I’ve written before, I’m concerned about the state of the PHP ecosystem. There are lots of good applications written in the language, but there is very little code sharing between different projects, mainly because of framework incompatibilities, but also because of quite a strong NIH culture.

The Aloha Editor Developer Conference is happening this week in Hacker Dojo, Mountain View. While some other events may steal a bit of focus from this one, there seems to be a good amount of energy here. The event opened with Haymo Meran's keynote on the state and roadmap of Aloha Editor. As part of this there was an interesting...
So, Google acquired PostRank, the service calculating impact of blog posts and other items in social media. If you want something similar but without the Google tie-in, then a good option is my social impact calculator which is fully free software written in PHP. It was originally written in 2007, but the newer version has been cleaned of Midgard dependencies...
contentEditable is the HTML5 feature that enables rich text editing on web pages. The original web browser that Tim Berners-Lee created was also a web editor, and contentEditable brings this possibility to all browsers.
Somehow I had missed this term being coined: The old "open vs. proprietary" debate is over and open won. As IT infrastructure moves to the cloud, openness is not just a priority for source code but for standards and APIs as well. Almost every vendor in the IT market now wants to position its products as "open." Vendors that don't...
you don’t have to know if you bet on Web-based applications. No one can break that without breaking browsing. The Web may not be the only way to deliver software, but it’s one that works now and will continue to work for a long time. Web-based applications are cheap to develop, and easy for even the smallest startup to deliver.—Paul...
The Bauhaus’s philosophy was that form should follow function and all other distractions and decoration should be avoided. It wanted space to be experience for its purity, stripped off all the ‘dirt’ and clutter of decor. This is something that’s been happening recently in the field of visual interaction design.—Interaction Design’s Bauhaus moment talks about the recent trend towards reductionist...
While PHP remains my primary programming language for various reasons, my recent projects have involved quite a bit of JavaScript development. And I have to say I like it: the event-driven paradigm is quite elegant, closures are a joy to work with, and tools like Node.js and jQuery really open up the possibilities of the language. But there is one...
In our Palsu collaborative meeting tool we’re using VIE for server-side page generation. This effectively means RDFa is our templating language. The CoffeeScript looks like the following:
My posts on Decoupling Content Management, and especially the introduction to the "build a CMS, no forms allowed" approach we took with Midgard Create have generated a lot of interest. When I first presented the approach in the recent Aloha Editor Developer Conference, many CMSs wanted to do something similar. And so we decided to strip the Midgard-specific parts out...
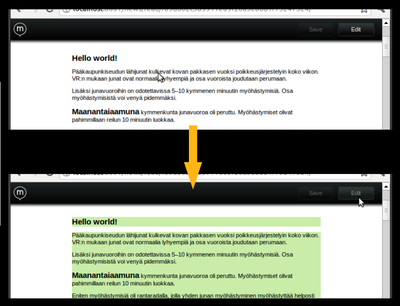
You may have noticed that quite a lot is happening in the Midgard land. Nowadays Midgard2 itself is a generic content repository that can be used for both desktop and web applications. Midgard MVC is a generic web framework for PHP5 that can be used with Midgard2 or without it. And then there is Midgard Create, the new content management...
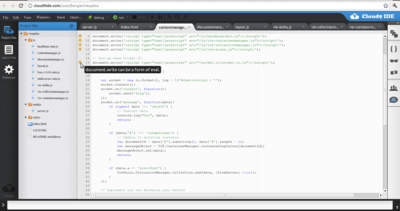
As I wrote in Better one file in the cloud than ten on the hard drive, when you mostly work on free software projects, then main frustration with a change of computer or a crashed harddrive is not lost files, but having to rebuild your development environment. The browser-based software development tool Cloud9IDE aims to solve that by moving the whole...

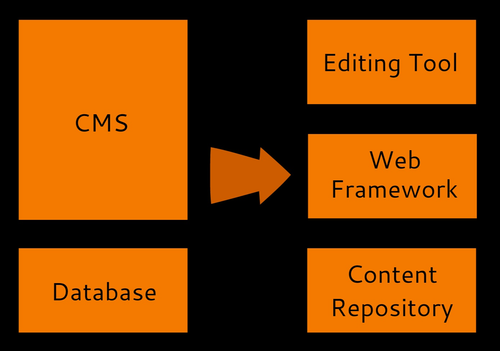
Traditional content management systems are monolithic beasts. Just to make your website editable you need to accept the web framework imposed by the system, the templating engine used by the system, and the editing tools used by the system. Want to have a better user interface? Be prepared to rewrite your whole website, and to the pain of having to...
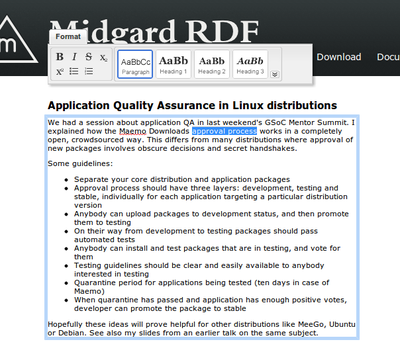
As part of the IKS project we're working on semantic web editing. One area there is using RDFa to actually make pages editable. RDFa is a way to embed semantic information to regular HTML pages, and is already supported by some search engines, making this also a way of doing SEO. But in addition to telling search engines what the...

Snapshot from Bertrand's presentation in the Amsterdam IKS workshop: what does being an Apache project bring to the table? The answer is sustainability. IKS is an EU-funded project which will eventually end. Proper project governance handled together with the Apache Software Foundation can help the software to survive and thrive for long after that. Sustainability is something that is critical...
More than 10% of all the websites in the world are run by Drupal, WordPress and Joomla — just these three. And all three are open source CMSs, so if you just count those three CMSs, you would lose 10% of the websites.
Want to work on the next generation of web editors?
Yet another interesting launch this winter: Google finally published their lifestreaming application, Buzz. These are still clearly early steps for the service as it doesn't provide any APIs yet, and the user interface feels slow in a quite un-Google-like way. However, it still shows strong potential in several ways. First of all, it may help the people raised on Twitter...
Joint post of Henri Bergius and Michael Marth cross-posted here and here. Web Content Repositories are more than just plain old relational databases. In fact, the requirements that arise when managing web content have led to a class of content repository implementations that are comparable on a conceptual level. During the IKS community workshop in Rome we got together to...
An increasing number of web services and applications are emphasising search terms or pre-selected websites instead of allowing users to enter any address they choose. This is worrying, as while searches are more user-friendly, URLs are the heart of an open web where anybody can publish without obscure business dealings or oppressive app store policies. There are many examples of...

Today I ran into the Open Collaboration Services API, planned as the vendor-neutral specification for Social Desktop services: Core idea of the Social Desktop is to connect to your peers in the community, making sharing and exchanging knowledge easier to integrate into applications and the desktop itself. The concept behind the Social Desktop is to bring the power of online...
This week is the Interactive Knowledge project general assembly and requirements gathering workshop in Salzburg, Austria. My notes from the meeting days can be found on Qaiku: Day 1: general situation, tasks and requirements Day 2: tools, persistent storage, meeting the community As things are happening, it is also possible to follow progress on the #iks-project Qaiku channel or the...
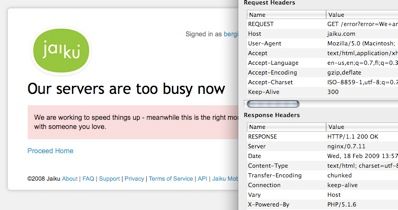
Jaiku, the microblogging service I use, has been frustratingly often down in the last couple of days, apparently kicking off another mass migration towards Twitter and Brightkite. And they report it only in human-readable way, not in fashion a browser, a proxy or a search engine would understand it. While being down, Jaiku still responds with HTTP 200 OK: HTTP...
Thanks to the IKS project, I've spent some thought lately in how to make something practical from the concept of Semantic Web. As always, the big issue is getting the semantic information out there. In a strongly typed CMS like Midgard, many semantics can be gathered from content structure directly, but to really get there we need users to add...

I spent this week at Salzburg Research in Austria attending the kick-off meeting of the Interactive Knowledge Consortium, a €6,5m EU-funded project to introduce semantic capabilities into open source content management systems. Nemein is participating in the project as one of the six industrial partners. For the next four years we will be working together with cool CMS companies like...
Let me share a little piece of Internet happiness: When I got my iPhone, I wondered how could its web browser be so dramatically faster than the one on my N810. Could it be just that iPhone has faster processor, and uses WebKit instead of Mozilla? But at the same time, the state-of-the-art Firefox 3 on my MacBook Air was...

At the moment the prevailing wisdom is that each CMS should have its own user interface, and that user interface should be web-based. But there is also another way: separating the user interface from the CMS using a CMS-neutral protocol called Neutron. According to Sir Tim Berners-Lee, the earliest web browser was also an editor. And the late 90s Netscape...
Sampo Pankki, the bank that was formerly known as Postipankki, Leonia and just Sampo was recently bought by the Danish Danske Bank. As part of the merger they switched their IT systems to Danske Bank infrastructure in a huge EUR 200 million operation over the Easter. The switch had a lot of issues, causing website downtime, faulty account data and...

Semantic web, the platform that could enable new businesses to rival the likes of Google has for a long time been a distant promise. Much of this has been because the standardization bodies have focused on too difficult and impractical technologies instead of building it on top of existing web implementations. Microformats are a more pragmatic approach: by using simple...
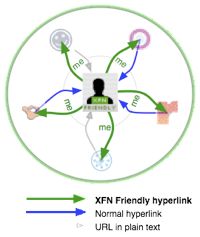
If you're using multiple social web services, you will also have multiple online identities. For creating a comprehensive online persona, consolidation between the various profiles would be useful. To aid in this, and to enable social network portability, Google has started aggregating social networking data marked up in the XFN and rel=me microformats to build a comprehensive social graph. Having...

Information overload is becoming a major issue, and more sophisticated solutions will be needed to tackle it. With Midgard we’ve already taken some steps into this space by creating tools for calculating newsworthiness of stories in order to present only relevant ones to a user.
Column Two has an interesting post titled What does a web CMS do? with a table listing features that are integral to a web CMS, and what can be handled separately.
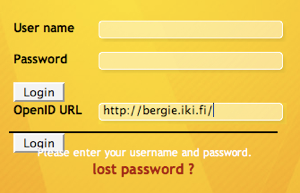
Inspired by a talk in FrOSCon on Sunday, I went and implemented OpenID support into Midgard on the flight back. OpenID is a quite cool system for cross-site single sign-on and auto-registration. With OpenID your user identity is tied to a web address you control, for example http://bergie.iki.fi/. Every time I want to log in to an OpenID-enabled website, that...

Greg Stein, of WebDAV, SVN and ASF fame, got violently mugged last Friday in Mountain View: They gave Greg a black eye and a serious laceration to the head which required numerous stiches. Apparently, he was bleeding profusely when the ambulance came. The doctors were worried about his head wound and he spent the entire night under observation and went...

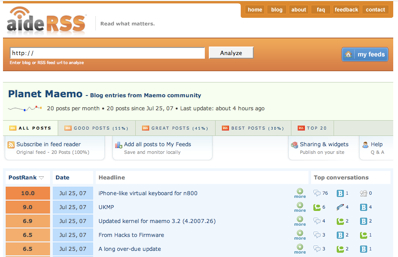
I’ve started working on a new Social News section for maemo.org. The idea of this area is to provide a centralized view on what is happening at the moment in the maemo community.
The fact that our VoIP provider has a proprietary closed network has bothered me for a while. In their N800 review, Spicy Gadget Roll put it well: The two instant messengers found in the N800 are Jabber and Google Talk. Both instant messengers are built on open standards, which I whole-heartedly believe in. There’s a lot of confusion as to...
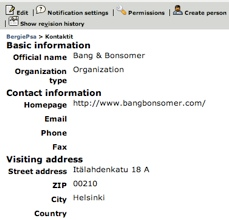
I’ve blogged earlier on how OpenPsa 2 can utilize information pulled from the websites of organizations and persons entered into the system.
Microformats are a cool way of making web content machine-readable. Since the formats rely on classes, they also ensure the content has all the hooks needed for good CSS design. Microformats can be understood by aggregators like edgeio and consumed with software like Firefox 3 and the Tails extension for Firefox 2. We have been introducing Microformats to all sites...
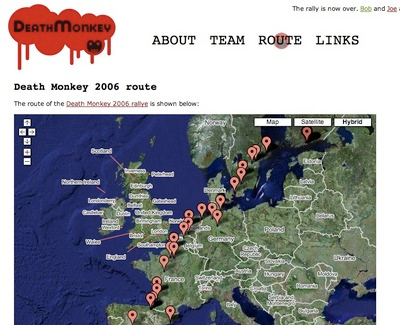
Midgard’s support for GeoRSS is solidifying with the auto-probing system in OpenPsa and the latest release of org.routamc.positioning.
I love the idea of including a “View Source” key into the OLPC keyboard:
I was one of the people interviewed for Jyrki Wahlstedt’s essay Managing Changes in Collaborative Innovation Networks. It deals with how innovation networks like free software projects communicate:
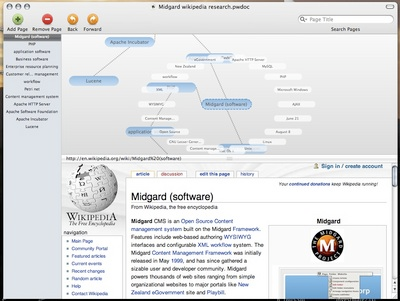
Pathway is an OS X desktop client for the Wikipedia, the free encyclopedia. It keeps track of relations between pages you read using a handy network map, and makes them searchable via Spotlight. It is also able to save the researched network of pages for later use.

September 22nd is the OneWebDay. It is a day when users of the World Wide Web are encouraged to show how the Internet affects their lives. The purpose of the event is to globally celebrate online life.

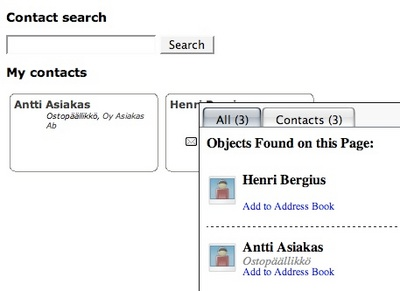
I’m now running Tails, a Firefox extension that recognizes and handles Microformats embedded in web pages. This means that if I browse to a compliant event calendar I can add an event there to my calendar with single click, or add contacts from a web page into my address book.
This should be obvious to most dealing with open source, but the example of Linux and others outlines three points for creating a successful free software project:
Two days and fifteen years ago, Linus Torvalds posted a message on comp.os.minix:
It seems that OSCON 2006 has sparked discussion about the relevancy of free software in the software as service world that Web 2.0 is taking us to. If all collaboration and data is tied to remote web servers controlled by some commercial entity, where do the four freedoms fit?
The GNOME desktop project from which Midgard also gets a bunch of libraries is now choosing a CMS for its website.
Growl is a very nice notification system for Mac OS X. It displays bubble-styled messages on the screen about various events like new instant messages or emails. We were looking for a new user interface messaging system for the Midgard web toolkit and decided to model it based on the Growl concept:
Tony Byrne of CMS Watch notes that there is nothing special about the web any more:
Looks like Apple is trying to patent RSS feeds and RSS auto-discovery:
Ben Hammersley has gone to the iWeb side, making his blog image-only. Some commentation is available:
I sent some notes to the Placeopedia team. Placeopedia is a service connecting Wikipedia pages with their locations on the map.
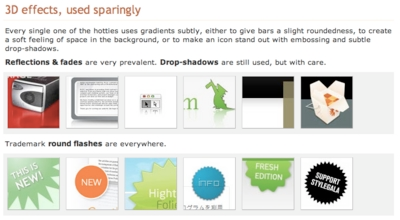
Web Design from Scratch has a pretty good analysis of the current style in web design:
I’m using Apple’s iPhoto on my PowerBook to manage the thousands of travel pictures. Lately the application has become very slow and unstable, and I was already preparing mentally to switch to F-Spot. Because of this, I was happy to hear that the new iPhoto 6 supports managing over 250k photos in the archive.
RSS syndication is a very useful technology that helps keeping track of hundreds of changing websites. With enclosure support it also enables fetching podcasts directly into your music player or software updates into the desktop.
Tigert has been sketching some Tango-styled UIs for the new Aegir admin interface of Midgard CMS:
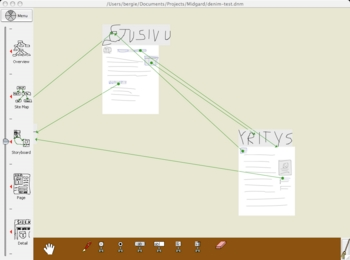
DENIM is an interesting, BSD-licensed desktop application from University of Washington. It allows web developers to sketch site and page structures easily with a stylus. Pages can be interlinked, and contain operable components like forms.
Zend, IBM and others have announced a collaboration project to create a Zend Framework using the following mission statement:
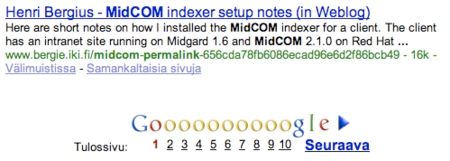
It seems that Google is now autodetecting PermaLinks of dynamically-generated pages using the rel="PermaLink" syntax. Here’s one of the results for my blog:
Taya pointed me to Software Freedom Day on September 10th:

The friday started with Esther Dyson’s breakfast talk about the importance of Internet for philanthropy and human interaction. After that we had the Online Publishing and Content Management with Open Source Software session chaired by Ryan Ozimek. Ryan and Usha Venkatachallam of Beaconfire opened the talk by introducing the audience to Open Source Content Management in general and then we...
Lots of Content Management Systems strive to provide meaningful URLs. With CMSs meaningful URLs usually mean mapping the internal content structure of the system to a filesystem-like tree hierarchy, which has the downside tying the URLs into the site structure. When the site structure is reordered the links can easily be broken. While sensible CMS deployments set up redirectors for...
The trailer of the Wyona Pictures movie F.U.D. - Fear Uncertainty Doubt documenting the Open Source community is now available. A BitTorrent client is needed for downloading.

We were thinking in OSCOM 4 about how to get the different Open Source CMS projects to feel more connected with the OSCOM process. One part of this was to get some link buttons that would make it easier for the projects to link to OSCOM. Marc Infield from Infield Design responded quickly to Gregor's request. Here are his OSCOM...
Apart from my own session, I went to see Danese Cooper's session on Corporate Blogging, which focused on how Sun uses blogs and other collaborative tools to aid in a cluetrainish transformation to a more customer focused and open organization. The related policies and success stories were a good starting point for convincing other companies to do the same. The...
After bit of thinking I decided that a session on MidCOM - Midgard's Component Framework for PHP would be a good match for the technical crowd here.Because of this most of my has been spent on setting up latest MidCOM on my iBook, tweaking my South AfricanMidgard training slides in SlideML to fit this conference, and marveling how slow the...
This conference is smaller than OSCOM 3 held in Harvard university and in about the same range as OSCOM 2 in Berkeley. However, this just means that this time most people attending are developers instead of end-users, and discussion ranges from interoperability topics to cultural issues. I'm chairing the Apache Track of the event. The first day was mostly Jakarta...

Today will be filled with arrangement practicalities, and the actual conference starts tomorrow at 9:15 am. All the previous OSCOM events I've attended have been fun, and I'm expecting an interesting three days filled with discussion, new CMS ideas, and quite a few presentations. Despite the early departure the flights went without incident, and I had time to read some...
In addition, Jakob Nielsen has posted an interesting piece on standard elements in web design. His recommendations include several conventions, like always placing a logo link to top-left corner and the search box to top-right corner.
More information can be found from the event press release:
Using standard CSS classes was one of the ideas I posted on practical CMS interop. If different Content Management Systems and web scripts could standardize on these keeping layouts synchronized between them would be very easy.In his follow-up, Andy provides a more detailed list and structure of IDs to use. This could well be the starting point for standardization.Updated 2004-06-23...
When standards-conscious designers validate their XHTML and CSS templates, everything is nicely compliant up until the point where they start tying in the necessary automated systems like ad software, CMSes, or e-commerce apps. The tools then get in the way and code is needed to fix validation, but a lot of designers dont code.
The patent abstract explains how a Web CMS works:
The theme of OSCOM.4 is "Cross-Pollination". This will be a conference with assistance from the Apache Software Foundation for the ApacheTracks content. The Open Source content management community is rich and varied with many projects such as OpenCMS, Plone, Midgard, Cofax, Drupal, and many others. Almost all Open Source CMS rely on software from the Apache Software Foundation (ASF), and...
From their blog entry:
One often forgotten aspect in OSCOM is that involvement in the process forces CMSs to evolve through a set of positive challenges.For example, the Midgard RSS aggregator used to suck until there was proposal that Planet OSCOM could be implemented with another solution. This lead me to improve the aggregator to a level where it works acceptably well.From #oscom:daveb: darn!...
The idea with collegiality is that badmouthing and competing in cut-throat fashion is not productive. What the competing systems should do instead is evaluate each others' strenghts and weaknesses objectively and embrace common protocols and standards for interoperability.This interoperability would enable users to build their own "Frankenstein CMS" by selecting best building blocks from different Open Source CMSs, or to...
MidCOM has been upgraded to the latest 1.3.0 releaseAegir has been upgraded to latest 1.0.3 nightlyRemoved unnecessary buttons from the "Edit this page" editor and added button for inserting imagesHTML <title />s on both OSCOM and Kupu front pages are now more descriptive, as supported by midcom-templateCSS has been fixed to show correct font size for tables also on IEPlanet...
As an analogy, the news reader acts like a customizable newspaper. You can pull a variety of content from a growing number of sources into one place, to be read however you choose. Sources like major news media outlets (BBC, Reuters, Washington Post) to non-news content providers (Apples iTunes Music Store, the Government of Canada, USGS World Earthquake updates) to...
WordPress is Free Software. Its rules will never change. In the event that the WordPress community disbands and development stops, a new community can form around the orphaned code. Its happened once already. In the extremely unlikely event that every single contributor (including every contributor to the original b2) agrees to relicense the code under a more restrictive license, I...
This method of web design is becoming increasingly popular, and for good reasons. For those who don't see the technical beauty of the solution as good enough reason, there are significant business benefits as well.We've worked on migrating our projects to standards-based design since last December, and the results look quite good. The only major issue is the mark-up produced...
While many pieces of web software already support unicode and other character-encoding standards theoretically, their way of interoperating using them might be disfunctional.Freedesktop.org runs the Project UTF-8, a resource for advocating unicode support in Open Source software. Maybe OSCOM should also do something in this space.Joel Spolsky has published a short how-to on what every programmer should know about unicode....
Here is the interview in English:WebDevMagazine: Can you tell me ore about OSCOM. What is the organization aim?OSCOM has two purposes, marketing and technical. On the marketing side, we aim to raise the public awareness in the availability and feasibility of Open Source Content Management Systems. This is what our first conferences focused on, and the reason why we maintain...
The rare spots where I've been able to explain the benefits of RSS have been:Keiretsu situations - displaying the news headlines from partner companies on a websiteIntranet headlines - displaying latest news items from the public site, running on separate serverHowever, this is still quite far from getting people from bloated news site browsing to the lean and efficient World...

OSCOM’s president Michael Wechner is one of the Twenty CMS Leaders to Watch in 2004 in a list published by CMSWatch.
Martin Langhoff’s OSCOM 3 presentation.
Jon Udell’s presentation at OSCOM 3:
Tony Byrne’s OSCOM 3 presentation:
Preparatory posting for OSCOM 3 regarding inter-CMS cooperation.
Discussing on how Open Source software might still amount to similar customer lock-in as proprietary systems
OSCOM is an international, not-for-profit organization dedicated to Open Source Content Management. The goal of the organization is to bring together as many great brains as possible to build a network and grow the community of open source content management.