Forget about HTTP when building microservices
Microservices — an architectural pattern we recommended in our 2012 International PHP Conference keynote — is pretty popular these days. There are many benefits to consider:
- Independent development and release lifecycle for each microservice
- Ensuring clear API boundaries between systems
- Ability to use technologies most applicable for each area of a system
In an ideal world, microservices are a realization of the Unix philosophy as applied to building internet services: writing programs that do one thing, and do it well; writing programs that work together.
Just use a message queue
However, when most people think about microservices, they think systems that communicate with each other using HTTP APIs. I think this is quite limited, and something that makes microservices a lot more fragile than they could be. Message queues provide a much better solution. This is mentioned in Martin Fowler’s Microservices article:
The second approach in common use is messaging over a lightweight message bus. The infrastructure chosen is typically dumb (dumb as in acts as a message router only) - simple implementations such as RabbitMQ or ZeroMQ don’t do much more than provide a reliable asynchronous fabric - the smarts still live in the end points that are producing and consuming messages; in the services.
When we were building The Grid, we went with an architecture heavily reliant on microservices communicating using message queues. This gave us several useful capabilities:
- Asynchronous processing
If you have heavy back-end operations or peak load, a microservice might be swamped with work to be done. If your web server only needs to send work to a queue and not wait for result immediately, you have a lot more freedom on how to organize the work. Furthermore, you can split your service along different scalability characteristics — some systems may be network-bound, others CPU-bound etc - Autoscaling
Since the work to be performed by your microservices is kept in message queue, you can use the combination of the queue length and typical processing times to automatically determine how many instances of each service you need. Ideally you can use this to ensure that your processing times stay consistent regardless of how many users are on your system at a given time - Dead lettering
It is possible to configure RabbitMQ to place any failed operations into a dead letter queue. This gives you a full record of any failing operations, making it possible to inspect them manually, replay later, or produce new tests based on real-world failures - Rate limiting
Sometimes you’re dealing with external HTTP APIs that are rate limited. Once a microservice starts hitting rate limits, you can keep new requests in a queue until the limit lifts again - In-flight updates
A message queue can be configured so that non-acknowledged messages go back into the queue. This means that if one of your services crashes, or you deploy a new version of it, no work gets lost. When the service is back up again, it can pick up right where the previous instance left off
Better tooling
HTTP is something all backend developers are familiar with. With message queues you have to deal with some new concepts, and hence new tools are also needed.
MsgFlo
Client libraries for talking with common message queues exist for pretty much every language. However, this still means that you’ll have to handle things like message pre-fetch limits, acknowledging handled messages, and setting up queues yourself. And of course keeping track of what service talks to what can become a burden.
We developed the MsgFlo tool to solve these problems. MsgFlo provides open source client libraries for bunch of different programming languages, providing a simple model to handle message-related workflow.
To give you an overview of the dataflow between services, MsgFlo also provides a way to define the whole system as a flow-based programming graph. This means you’ll see the whole system visually, and can change connections between services directly from graphical tools like Flowhub.
If you’re using Heroku, MsgFlo can also generate the Procfile for you, meaning that the services you’ve defined in your graph get automatically registered with the platform.
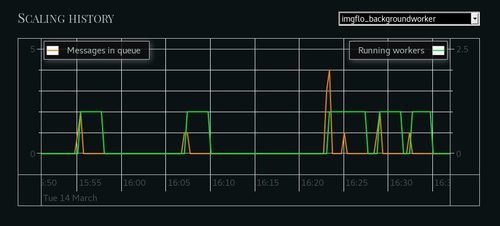
Guv
As mentioned above, queue-based microservices make autoscaling quite easy. If you’re on Heroku, then our Guv tool can be used to automate scaling operations for all of your background dynos.
I wrote more about GuvScale in a recent blog post.
Further reading
If you’d like to explore using message queues for your services a bit more, here are couple of good articles:
There are also some MsgFlo example applications available:
- msgflo-example-imageresize is a web service for scaling images using autoscaled background workers
- imgflo-server is a web service that uses MsgFlo to send image processing jobs to background GEGL or NoFlo microservices
Continue reading

The Grid: Web Design by Artificial Intelligence