Why did I reimplement Jekyll using NoFlo
Jekyll is a delightful piece of software. A Ruby application that turns your Markdown and HTML files to a nicely constructed static website. Since the generated site is static, you can deploy and serve it from anywhere with no security or performance concerns. As a matter of fact, this site is built with Jekyll.
For websites that don’t need to offer dynamic functionality this is in many ways the culmination of Decoupled Content Management — you can write the post using whatever editor, use GitHub as the content repository, and deploy the pages to any web server you want.
If you’ve been to our Kickstarter project you probably know that I’ve reimplemented Jekyll using the NoFlo flow-based programming environment. If I’m so happy with Jekyll as it is, why would I do such a thing?
Introducing noflo-jekyll
Before I go to the reasons, let me briefly introduce the project itself: noflo-jekyll
Just like any flow-based program, the NoFlo reimplementation of Jekyll is built out of a graph. Here is how the main graph of the application looks like when loaded via the NoFlo UI prototype:
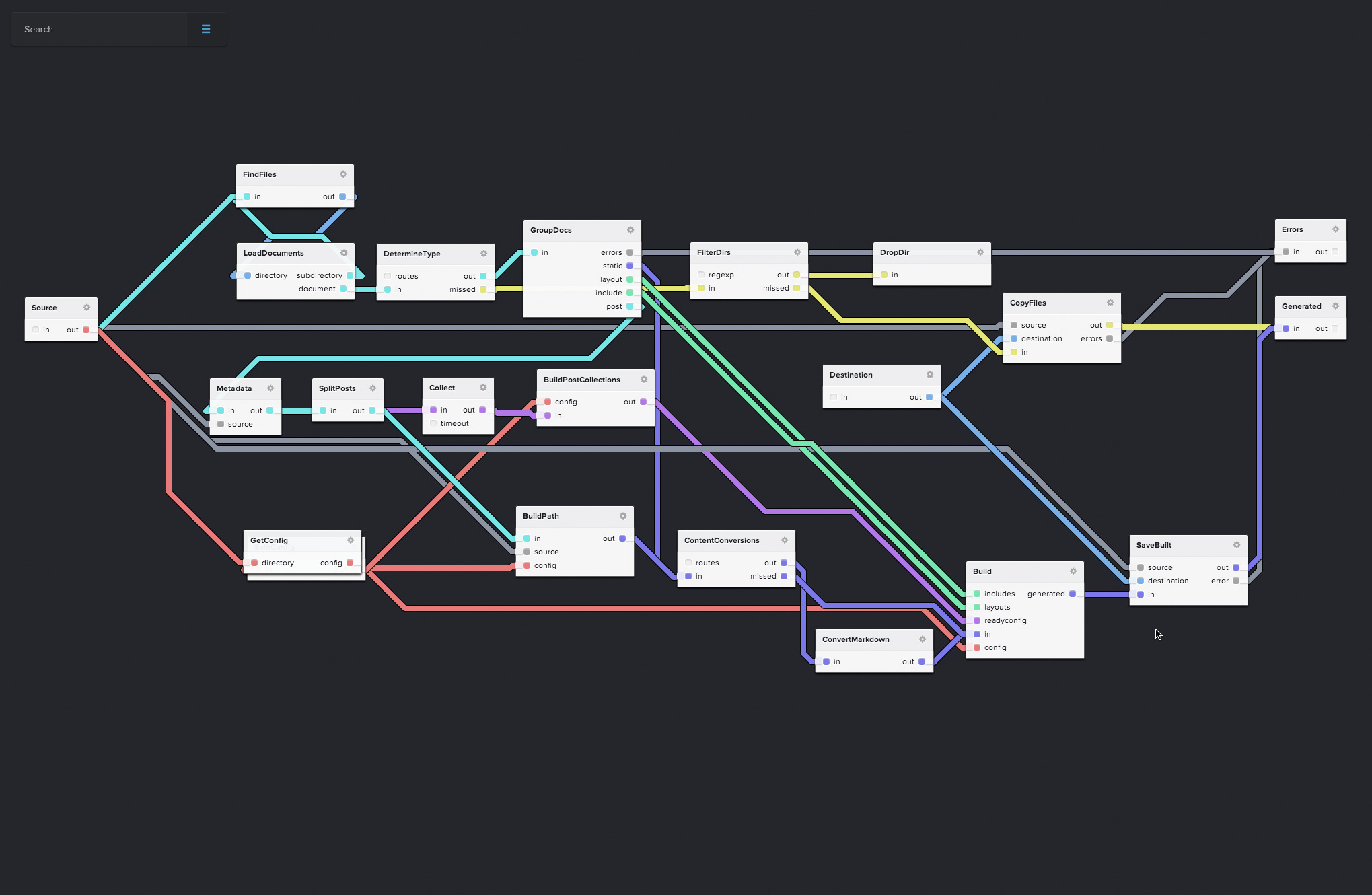
Quite a few of the boxes you see in that graph are actually subgraphs. Since the UI is still under work, the subgraphs have been defined in the more text editor friendly .fbp syntax.
In total at the current version the graphs contain 107 nodes. Most of these running a component from the extensive NoFlo component libraries, but there are also 4 custom components built for this project. These components put together are under 500 lines of code, and everything else is using 100% reusable code from existing libraries. Not bad compared to the size of the original Jekyll code base at over 16k LoC!
You can grab the first release of noflo-jekyll right now from NPM. Please refer to the README on how to use it.
Where this is coming from
When I started working with the rest of The Grid team last year, Jekyll development had practically stopped. It looked like nothing was happening in that community. Since Jekyll was something we very much wanted to utilize for various projects, the situation looked a little bit risky.
Since we’re very much a NoFlo shop, it felt natural to take Jekyll as sort of a specification, and reimplement it using FBP techniques. Initially this was an internal effort, but then we decided, very much in the nature of GitHub’s “open source (nearly) everything” philosophy, that this should be opened as well.
I got noflo-jekyll into a running state in about a week, and then moved my attention to other things we needed to build. And so the finishing touches and a public release were postponed to a better day.
As it happens, Jekyll development resumed pretty soon after that. But there are still many reasons why noflo-jekyll can be quite cool.
Benefits of the NoFlo port
Here are some reasons why especially Node.js developers should care about this project:
- Pure JavaScript, no need for Ruby or other runtimes in your environment. Especially handy if you’re using Grunt for site generation
- Other data sources, in NoFlo everything is just a flow of data. You could easily plug in other data sources than the file system. For example, database query results
- Different converters, don’t want to use Markdown? Just plug in your own mark-up processor component
- Different template engines, don’t want to use Liquid? Just plug in your own template processor component
- Use as library or executable, this Jekyll implementation is just a NoFlo graph. You can use it in other NoFlo applications, as a Node.js module, or as a command-line executable
However, as with any reimplementation of a application being actively developed, there are also some potential caveats to observe.
A NoFlo example
Most of the existing NoFlo applications out there are dealing with various business processes, and so very little of that is available out in the open. As such, noflo-jekyll can probably show how to build bigger systems out of flow-based graphs, and also how to connect them with the rest of the Node.js ecosystem.
noflo-jekyll is now available under the MIT license for your static site generation needs. But as it happens, it wasn’t the only interesting NoFlo example to be released this week. You may want to also check out how to handle HTTP requests in NoFlo with the Woute module. There is even an example project available.
Keeping up with Jekyll
To realize the benefits of flow-based static site generation, it is quite important to keep the NoFlo reimplementation up-to-speed with things changing in Jekyll-land.
Because of this, the most important part of our automated tests is comparing results between a site generated by the original Jekyll program, and the NoFlo version. This means that when new features are added to Jekyll, we can follow the red-green-refactor style of test-driven development, and add these features to the test site.
I’ve been happily building my blog and the NoFlo site with this for a while, and except for some minor templating and Markdown handling differences between the Node.js and Ruby versions of those libraries, things are looking solid. If you find something that doesn’t work with the site or templates you have, please let us know!
Continue reading
NoFlo: two years of flow-based programming
